[ICML18] Born-Again Neural Networks
Abstract (Motivation)
현대 딥러닝 모델들은 다양한 module (layer)가 결합되면서, 점점 많은 계산 비용을 유발한다는 문제가 있다. 하지만 언제나 무거운 모델만을 사용할 수는 없는 법... GPU의 가격은 상상을 초월하므로 가벼운 모델들에 관심을 가져볼 필요가 있다.
그렇다면 어떻게 가벼운 모델을 만들 것인가? 이에 대한 연구 분야 중 하나가 Compression (압축)이라고 볼 수 있다. 여기에는 Pruning ([1]), Quantization 등 다양한 소분야가 있지만, 오늘 리뷰할 논문은 Knowledge Distillation (KD)에 관한 논문이다.
KD는 쉽게 풀자면, "고성능의 (high-performance) 선생님 (Teacher) 모델을 기반으로 학생 (Student) 모델를 학습시키면 Teacher의 성능은 어느 정도 유지하면서, 구조는 더 작으므로 더 좋은 architecture를 만들 수 있다."라고 볼 수 있다.
다시 말하자면, Student (small-model)가 아무것도 모르는 상태에서 시작하는 것보다, Teacher (large-model)의 정답을 먼저 학습시킨 뒤에 공부를 시작하는 것이 더 효과가 좋다는 것이다.
이러한 특성 때문에, KD를 컨닝이라고 인용하는 문서도 상당히 많다.
Introduction - KD
조금 더 깊게 들어가보자. 아래 사진은 KD의 기본이라고 볼 수 있다.
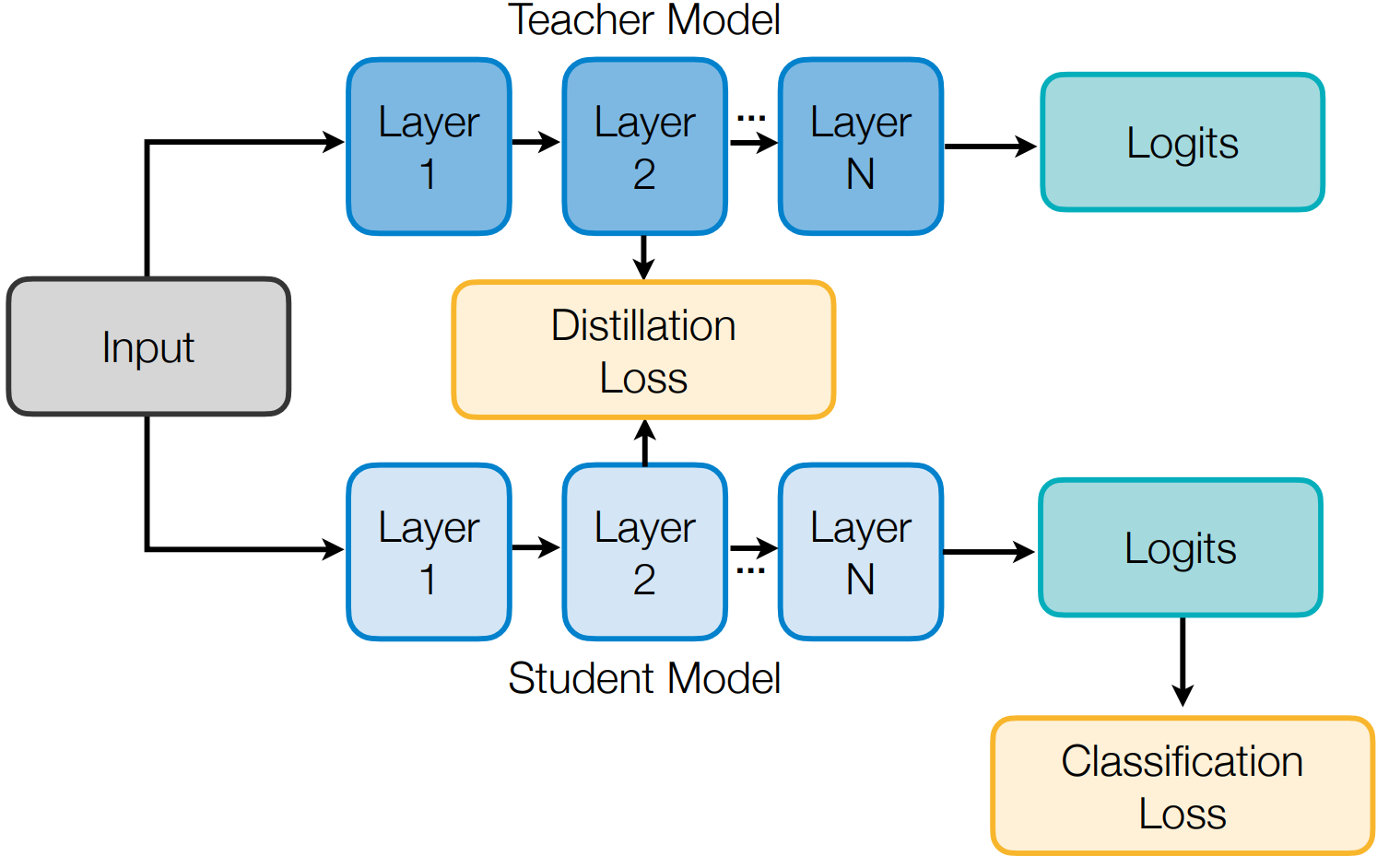
Teacher, Student는 공통적으로 3개의 Layer를 가지고 있다. 여기서 주목할 점은, Layer's name (e.g., Transformer, Convolution)은 변하지 않는다는 것이다.
Student가 학습하려면 Teacher가 필요하다고 언급했둣이, 우선 Teacher을 학습시킨 뒤에 Student가 학습을 시작할 수 있다. 따라서, Logits을 구하는 과정까지 학습을 시켜야 한다.
여기서 Logits은 Teacher가 학습 중에 각각의 layer를 통과했을 때 나오는, output을 의미한다.
이제 Student는 output (Teacher가 학습했던 내용)을 통해서 학습을 시작할 수 있다!
이 과정에서 더 가벼운 모델을 만들기 위해 구조적 변형이 생긴다. 또한 그 과정에서 성능이 떨어지는지를 Distillation Loss를 통해서 지속적으로 확인한다. (Recurssion)
Student가 효과적으로 학습을 끝냈다면, Teacher와 비교했을 때 "성능이 어느정도 유지되면서 더 가벼운 모델 (refined Student)"을 얻을 수 있다.
Introduction - Born-Again Neural Networks (BANs)
Pruning, Quantization처럼 KD는 일종의 Compression (압축) 기법이라고 할 수 있다. 성능은 유지하면서 더 가벼운 architecture를 찾는 일련의 과정이라는 것이다. 그런데 과연 이 방법이 최선일까? 다시 "Introduction - KN" 로 돌아보자. 그 과정 중에는 아래의 Recurssion (반복)이 존재한다.
이 과정에서 더 가벼운 architecture을 만들기 위해 변형이 생긴다. 또한 그 과정에서 성능이 떨어지는지를 Distillation Loss를 통해서 지속적으로 확인한다. (Recurssion)
즉, Student가 학습하는 과정에서 Teacher (무거운 모델)이 지속적으로 사용되므로 2개 모델이 동시에 사용된다고 볼 수 있다. 우리는 가벼운 모델을 찾기 위해서 KD를 하는 것인데, 찾기 위해서 계속 무거운 모델을 활용해야 할까? 이건 배보다 배꼽이 더 큰 상황이 아닐까?
BANs는 이 질문에 대한 해답으로써, "단 한번만 Teacher를 활용"한다는 획기적인 방법을 제시한다. 심지어 "Student는 Teacher의 성능을 뛰어넘을 수 없다"는 기존의 한계를 뛰어넘어서, 통계학을 기반으로 Teacher보다 더 높은 성능의 Student를 실험 (CWTM, DKPP)을 통해서 입증한다.
Main Concept
Initial Approach : self-validatoin
Self-validation은 머신 러닝에서 꽤 익숙한 개념이다. "모델을 학습시킬 때, 학습용 데이터 (train) 일부를 검증용 (validation)으로 사용해 학습하면서 검증한다면, 그렇지 않을 때보다 over-fitting을 방지하므로 일반적인 성능이 개선된다"는 맥락이며, K-fold Cross Validation은 그 응용 버전이라고 볼 수 있다. 또한 논문에서는 "self-validation과 함께 self-ensemble까지 적용하면 성능이 더 개선된다"는 점을 언급한다.
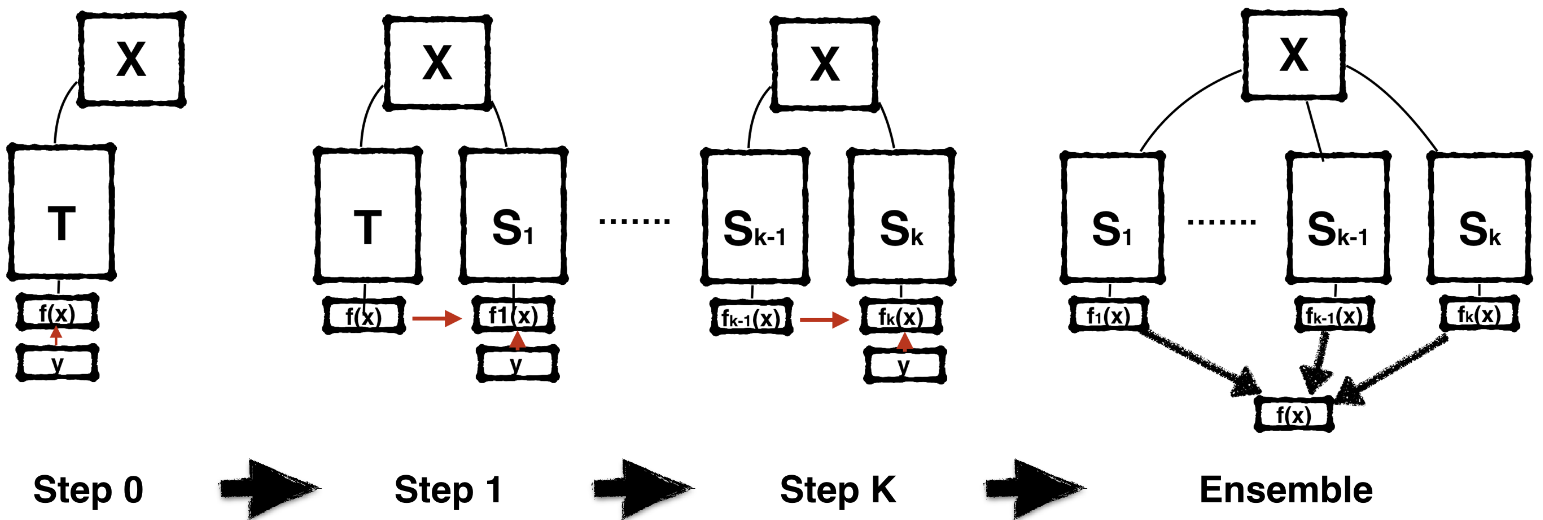
Main Concepts : Sequence of Teaching BAN
BANs의 과정은 아래와 같이 요약할 수 있다.
첫 학습에서, Teacher (T)는 오직 Ground Trouth (GT)만을 별도로 저장한다.
Initial Student (
S_1)는 오직 T의 logits 만을 학습한다.(Recurssion) k번째 S는 k-1번째 S의 logit으로 부터 self-validation을 통해 학습한다.
차근차근 정리해보자. 우선 논문에서 정의하는 아래 내용의 GT에 대해서 짚어볼 필요가 있다.
Ground Truth (<> dark knowledge term) : corresponds to a simple rescaling of the original gradient that would be obtained using the real labels
이 내용을 풀어보자면, "real-label (정답)"이면서, 동시에 "simple-rescaling"이 가능한 일종의 매개변수임을 알 수 있다. 다시 말하자면, recurssion을 통해서 새로운 Student를 생성할 때 오답을 학습시키지 않으면서, 더 가벼운 architecture을 만들기 위해서 rescaling이 가능한 경우만을 추출한다.
이 조건에서 추출할 때, logits (output of model, See alsoIntroduction - KD)도 함께 추출한다.
자 이제 Teacher에게서 유용한 정보를 추출했으므로, Student를 만들 차례이다. 지금까지의 내용을 기반으로 loss function을 활용해, Student를 생성한다. 여기까지는 기존의 KD와 다른 점이 없다.
그리고 주목할 점은 그 다음 단계인, 과정3이다. 중요하므로 다시 써보자면, 아래와 같다.
(Recurssion) k번째 S는 k-1번째 S의 logit으로 부터 self-validation을 통해 학습한다.
이제 다음 Student를 생성하는데, 이 과정이 기존에 생성되었던 Student를 기반으로 self-validation을 통해서, 또는 여기에 self-ensemble까지 한 뒤에 next Student을 생성한다는 것이다.
Main Concept : Ensemble for BAN
Ensemble은 머신러닝에서 익숙한 개념이기 때문에 가볍게 넘어갈 수 있지만, 논문에서 언급되지 않은 "연산랸 과부하 가능성"에 대해서 생각해볼 필요가 있다.
물론 Ensemble을 통해서 성능이 개선될 수 있지만, Ensemble은 여러 개의 프로세스를 한 번에 수행하는 과정이므로 이 과정에서 연산량 과부하 (Out-Of-Memory)가 올 수 있음을 인지해야 한다. (이를 해결하기 위해 Distributed-Training, Binarization 등의 후속 연구가 있을 것으로 개인적으로 예상한다.)
Conclusion
이 논문은 기존의 KD에서 있었던, "Student를 생성하는 과정에서, 지속적으로 Teacher를 사용되므로, 그 과정에서 비용이 높다"는 문제를 극복하고자 한 논문이다. 이를 위해서 Teacher를 최소화하는 self-distillation 연구들이 있어왔지만, 성능이 감소했다는 한계가 있었는데, BANs는 그 성능을 뛰어넘으면서 SOTA를 기록했기에 의미가 있다고 볼 수 있다.
후속 연구로 예상되는 부분 중 하나는 logits 최적화인 것 같다. Student가 학습할 정답지에 가까운 내용이므로, 이를 어떻게 최적화할 것인가?라는 질문에 대한 대답이 분명히 있을 것이고, 앞으로 KD의 다른 논문들을 읽어볼 때 이런 맥락에 집중하면서 보면 도움이 될 것 같다.
See also
[1] EIE paper review : Pruning과 관련된 논문을 리뷰했던 게시물입니다.