Introduction
앞으로 데이터셋을 보다보면 결측치 즉, 데이터 속성값이 Null인 값을 많이 볼텐데 Null값을 학습시 모델에게 주입하게 된다면 제대로 된 모델이 만들어지지 않을 가능성이 크다. 이번에는 결측치를 처리하는 3가지 방법에 대해 알아보고 3가지 방법 중에 어느 방법이 더 적은 MAE를 나타내는 지 알아보자.
Three Approaches
A Simple Option : Drop Columns with Missing Values
3가지 방법 중에 가장 간단한 방법 중에 하나로 Null 값이 존재하는 속성 값의 열의 아예 버려버리는 방법이다.

남은 2가지 방법도 후술하겠으나, 3가지 방법 중에서는 가장 버려지는 값이 많은 방법이므로 상대적으로 MAE가 커져 모델의 정확도가 정확한 방법에는 미치지 않을 것이다.
A Better Option : Imputation (결측값 대체)
대입은 누락된 값을 임의의 숫자로 채우고 모델로 학습하는 방법이다.
예를 들어, 누락된 값에서는 각 열의 평균값을 넣기도 한다.
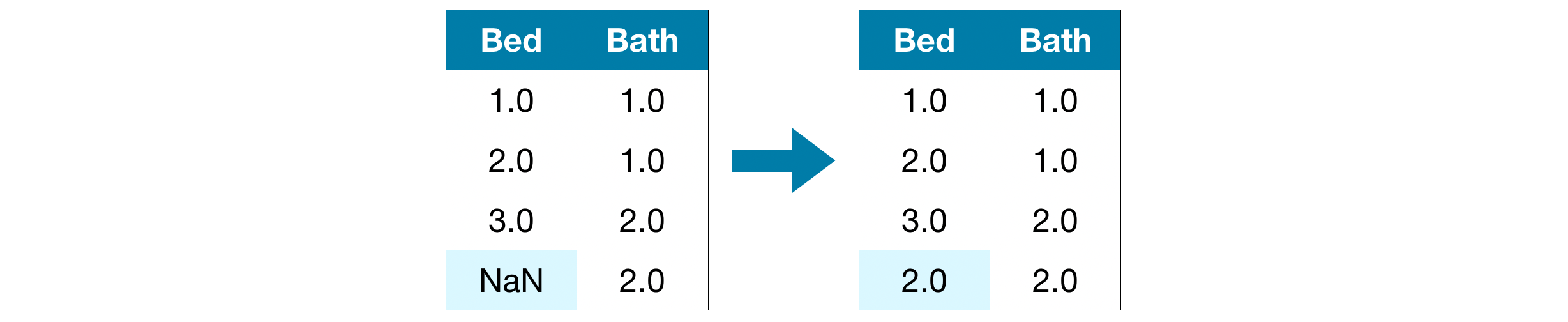
이런 평균 추산 대입 방법 또한 정확하지 않은 방법이지만, 기존에 말했던 열을 탈락시키는 방법에 비해 보존되는 기존 열의 값이 있기 때문에 더 나은 모델을 가질 수 있다.
An Extension To Impution
대입은 표준적인 접근 방법이며 일반적으로 잘 작동한다. 그러나 대입된 값은 실제 값보다 높거나 낮을 수 있는 등 정확도가 낮을 확률이 우세하다. 또는 결측값이 있는 행이 다른 방식으로 고유할 수도 있다. 이 경우, 모델은 원래 결측 값이 무었인지 고려해 더 나은 예측이 가능할 수도 있다.
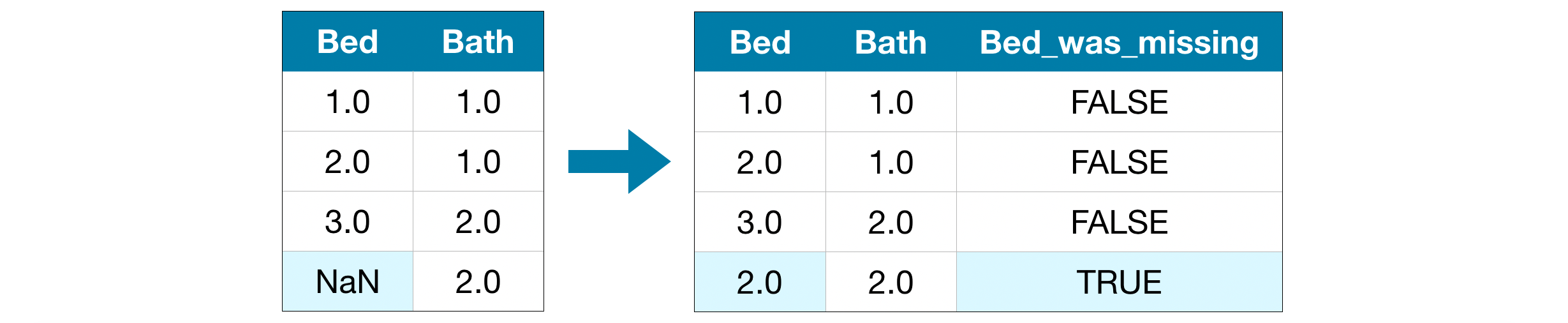
이 방법에서는 이전과 마찬가지로 결측값을 대입한다. 또한, 원본 데이터셋에서 결측 항목이 있는 각 열에 대해 대입된 항목의 위치를 나타내는 새 열을 추가힌다.
어떤 경우에는 결과가 의미 있게 향상될 수 있지만, 어떤 경우에는 전혀 도움이 되지 않는다.