LangChain
LLMs로 구동되는 애플리케이션을 개발하기 위한 프레임워크
RAG
Retrieval-Augmented Generation (검색-증강-생성)
최신정보에 대한 학습을 하고 싶을때
제한된 내부데이터에 대한 학습을 하고 싶을때
특정 도메인에 대한 질문을 할 때
문서화 시켜 기대하는 답변이나 환각 현상을 없애고 싶을때
-> 궁극적으로 더 나은 답변 품질을 기대할 수 있으며, 방대한 지식 기반으로 답변하는 도메인 특화 챗봇을 생성하는 것이 가능하다.
토큰
자연어 처리에서 텍스트를 작은 단위로 나누어 처리하기 위해 사용되는 기본 단위
단어, 부분 단어, 문자 등이 토큰이 될 수 있음
LLM에서 토큰은 텍스트 데이터를 모델이 이해하고 처리하기 위해 분할된 기본 단위
BPE 알고리즘 등으로 자주 등장하는 문자 쌍을 합쳐가며 서브워드를 생성
토큰의 중요성
토큰화는 자연어 처리의 기본적인 단계 로 LLM을 이해하고 사용하는데 필수적인 개념
다양한 토큰화 방법을 잘 이해하면 모델 성능 최적화에 도움
어떤 방식이 사용되느냐에 따라 모델의 성능과 효율성이 달라질 수 있음
토큰화 방법을 선정할때는 모델의 목적에 따라 선정해야함
Context Window
입출력을 처리할 수 있는 최대 토큰 길이
max_tokens : 답변에 대한 최대 출력 토큰 수
입력과 출력의 비용은 다름
LangChain 문법
ChatOpenAI 주요 파라미터
temperature
max_tokens
model_name
llm.invoke 함수 사용
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv()
llm = ChatOpenAI(
temperature=0.1,
model_name='gpt-4o',
)
question = '미국의 수도는?'
print(f"[답변]: {llm.invoke(question)}")
답변에 굉장히 많은 내용이 나옴
AImessagesms 객체로 나오게 됨


content key값으로 접근하면 깔끔하게 답변 출력 가능
logprobs=True
각 토큰의 확률값을 확인 가능
스트리밍 출력
실시간 출력 및 출력 답변 저장
question = "데이터 사이언티스트의 역량 3가지만 알려줘"
# 1. 전체 내용을 담을 빈 문자열 변수 생성
full_response = ""
print("[실시간 출력 시작]")
# 2. 스트림으로 한 조각씩 가져오기
for chunk in llm.stream(question):
content = chunk.content # 조각의 내용 추출
print(content, end="", flush=True) # 화면에 실시간으로 출력 (end="" 필수)
full_response += content # 전체 내용을 변수에 차곡차곡 저장
print("\n\n[스트리밍 종료]")
print("-" * 30)
##############
# 3. 나중에 한 번에 출력하거나 다른 용도로 사용
print(f"변수에 저장된 최종 내용:\n{full_response}")
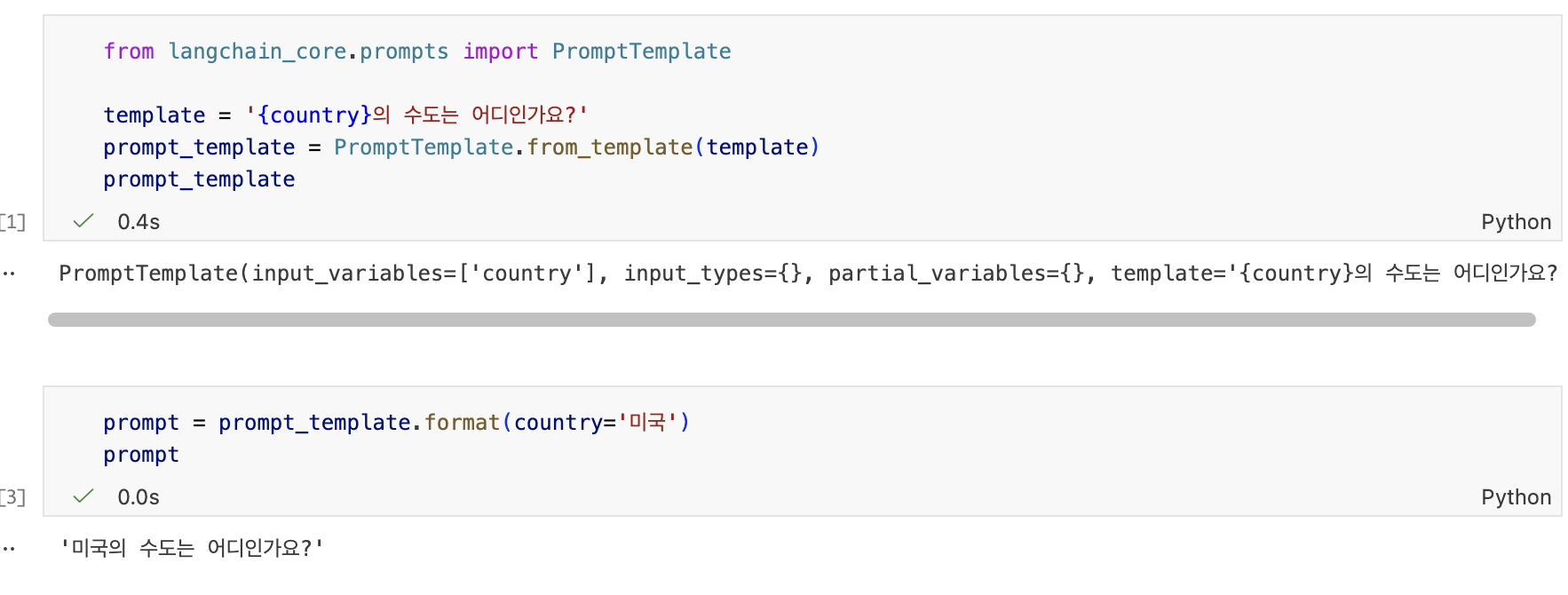
프롬프트템플릿
PromptTemplate
사용자의 입력 변수를 사용해 완전한 프롬프트 문자열을 만드는 데 사용되는 템플릿
사용법
template: 템플릿 문자열, {}는 변수를 나타냄
input_variables: 중괄호 안에 들어갈 변수 이름을 리스트로 정의
from langchain_core.prompts import PromptTemplate으로 사용