멀티스레드를 이용한 가비지 컬렉션 구현 중 STL 코드(vector의 소멸 등)에서 계속 느려지는 현상을 겪었다. 깔끔하게 설명해주는 자료를 찾지 못해서, 조금이라도 이해하기 위해 예제 코드를 만들어 정리하기로 했다. (혹시 이 글을 읽으시는 분들 중 정확한 정보를 알고 계신다면 알려주시면 감사하겠습니다!)
class Foo
{
public:
std::vector<Foo> childs;
};우선 vector 를 멤버변수로 갖는 class Foo 를 만들었다.
int main()
{
int objectCount = 10000000;
std::vector<Foo*> objectBox;
objectBox.reserve(objectCount);
for (int i = 0; i < objectCount; i++)
{
objectBox.emplace_back(new Foo());
}
auto Start = std::chrono::high_resolution_clock::now();
// 테스트 케이스 넣기
auto End = std::chrono::high_resolution_clock::now();
auto Duration = std::chrono::duration_cast<std::chrono::milliseconds>(End - Start);
std::cout << objectCount << "개 총 삭제 시간 : " << Duration.count() << "ms" << std::endl;
}오브젝트는 10,000,000개를 생성하고, 중간에 테스트 케이스를 넣어 문제를 확인해보자.
Debug Mode - Single Thread
for (int i = 0; i < objectCount; i++)
{
delete objectBox[i];
objectBox[i] = nullptr;
}메인스레드에서 반복문을 돌며 Foo를 소멸시킨다. 2500ms 정도가 나온다. 나의 경우, 이 상태에서 성능 개선을 위해 스레드를 도입했었다.
Debug Mode - Multi Thread
void Work(std::vector<Foo*>* objectBox, int chunkSize, int index)
{
int startIndex = chunkSize * index;
int endIndex = chunkSize * index + chunkSize;
for (int i = startIndex; i < endIndex; i++)
{
delete (*objectBox)[i];
(*objectBox)[i] = nullptr;
}
}
// main ----------------------------------------
std::vector<std::thread> workers;
for (int i = 0; i < 5; i++)
{
workers.push_back(std::thread(Work, &objectBox, objectCount / 5, i));
}
for (auto& iter : workers)
{
iter.join();
}다섯개의 스레드를 만들고, 각각 인덱스를 나누어 오브젝트를 소멸시키도록 했다.
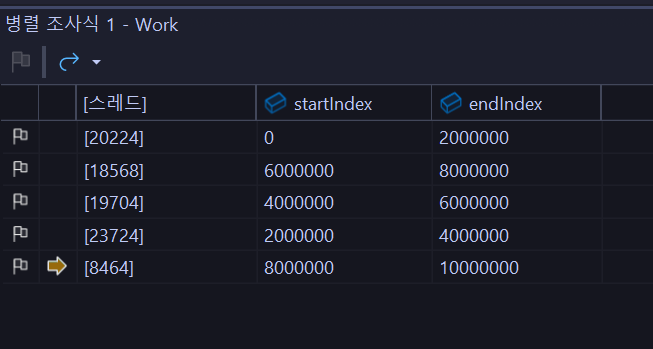
똑같은 벡터를 참조하곤 있지만, 나는 인덱스를 나누어 동기화 문제가 없도록 했다. 당연히 스레드를 늘리면 속도가 훨씬 잘 나올거라고 예상했는데 충격적이게도 평균 속도는 6500ms 가 나왔다. 단일 스레드의 2배를 넘는다. 처음엔 스레드 생성 비용이나 join 하도록 기다리는 부분이 시간이 오래 걸리는 줄 알았는데, 스레드풀로 변경해봤지만 의미있는 성과를 얻지 못했다. 왜 같은 양의 객체를 삭제하는 작업임에도 불구하고 다중 스레드 환경에서 훨씬 많은 시간이 드는건지..
릴리즈 모드와 비교해보자
같은 코드를 릴리즈 모드로 변경하고 돌려봤다. 놀랍게도.. 평균적으로 단일 스레드는 220ms, 다중 스레드는 85ms정도가 나온다. 생각대로 작동하는 것을 알 수 있었다. 왜 디버그 모드와 릴리즈 모드에 이런 차이가 발생하는 걸까?
__acrt_lock(__acrt_heap_lock);
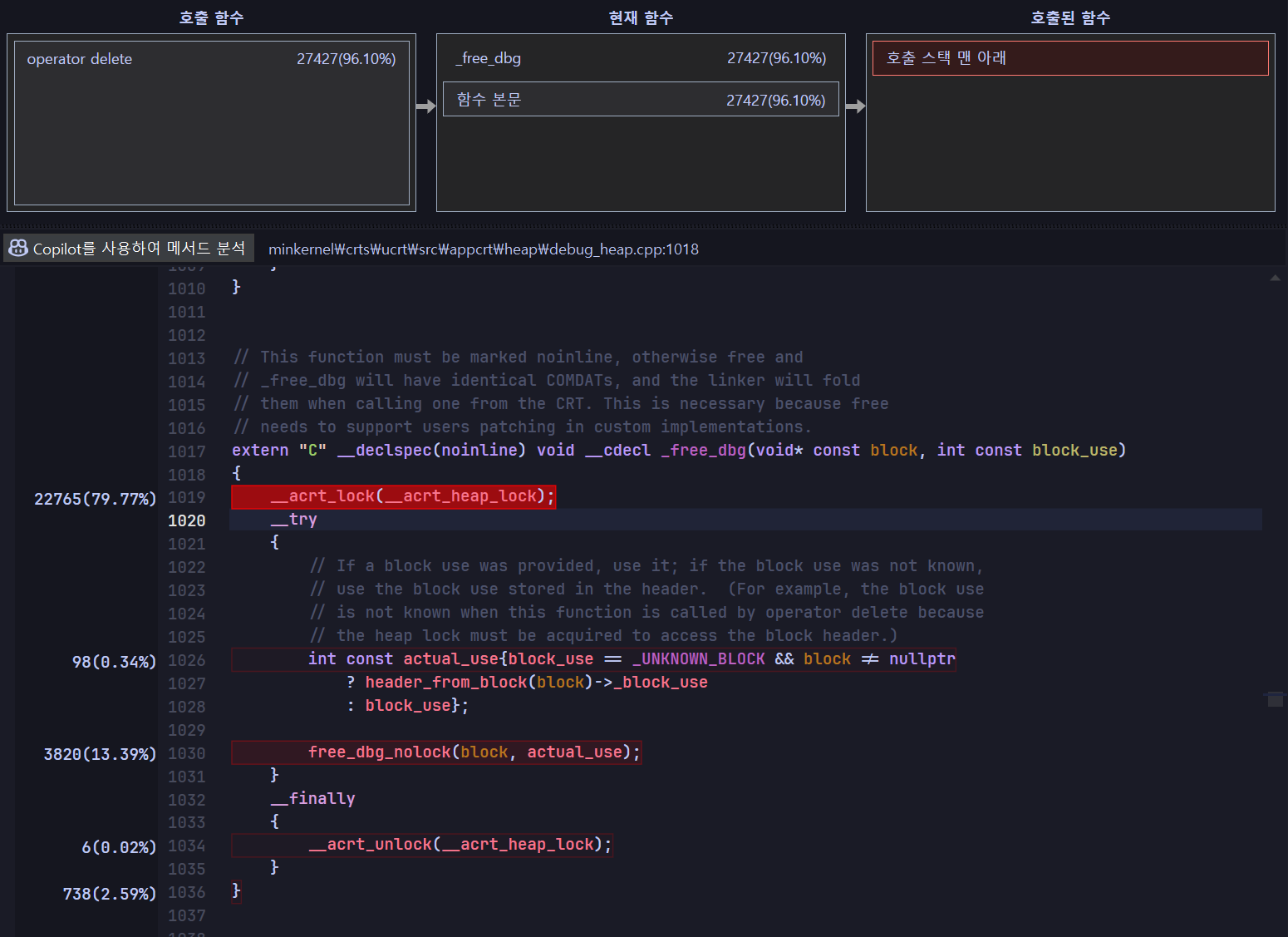
디버그 모드의 다중 스레드 코드에서 시간이 가장 많이 걸리는 곳을 찾았다. GPT는 이 부분이 메모리 해제 작업 중에 여러 스레드가 동시에 힙을 수정하지 못하도록, 힙에 대한 전역 락을 획득하여 동기화 문제를 방지하는 역할을 한다고 한다.

릴리즈 모드에서 진단 도구를 사용할 수 없어서 명확하게 알기는 어렵지만, 추측해보자.
std::vector는 내부적으로 요소를 저장할 동적 배열을 관리한다. 하지만 디버그 모드에서는 해당 벡터 내에 요소가 없다고 하더라도 디버깅을 위한 추가 코드나 힙 할당, 락 동작 등이 추가될 수 있다. => 다중 스레드 환경에서 락 경쟁 및 추가 오버헤드로 인해 단일 스레드보다 성능이 떨어질 수 있다.
결론
디버그 모드에서는 단일 스레드에서도 벡터를 사용할 때 디버그용 검사와 동기화 코드로 인해 락이 걸리지만, 다중 스레드를 사용하면 여러 스레드가 동시에 락을 획득하려 하면서 락 경쟁이 발생하여 단일 스레드보다 성능이 떨어진다.
릴리즈 모드에서는 디버그용 검사와 동기화 코드가 제거되고 최적화가 적용되므로, 동일 작업에 대해 멀티스레드를 사용하면 속도 향상을 얻을 수 있다.
이 문제를 디버그 모드 내에서 해결하기 위해, 나는 boost의 small_vector 라이브러리를 이용했다. small_vector는 요소의 수가 인라인 용량 내에 존재하면(즉, 벡터가 관리하는 동적 배열이 객체 내부에 존재하면) 별도의 힙 할당이 발생하지 않는다. 디버그 모드에서 동적 할당 시 추가적인 디버그 검사와 락이 삽입되는 문제를 우회하여, 성능 문제를 해결할 수 있었다.