Preliminaries
딥러닝 학습 시 입력 데이터의 분포가 일정하게 유지되는 것은 학습 안정성에 큰 영향을 준다.
활성화 함수는 입력 값의 범위에 따라 미분값이 크게 달라지는데, 입력 값의 분포가 일정하면 활성화 함수가 항상 유사한 동작 구간에서 작동하게 되어 미분값의 크기도 안정적으로 유지된다. 이는 역전파 과정에서 gradient가 과도하게 소실되거나 폭발하는 현상을 완화하여 학습 안정성으로 이어진다.
또한 입력 분포가 흔들리면 그 영향이 역전파 과정에서 레이어를 거치며 누적되고, optimization 과정에서는 미분값의 크기에 의해 실제 파라미터 업데이트(step size)가 크게 변할 수 있다. 따라서 학습 안정성 측면에서 입력 데이터의 분포를 일정하게 유지하는 것이 중요하다.
BatchNorm
Batch Normalization 은 학습 과정을 전체적으로 안정화하기 위해 층의 출력을 정규화한다. 정규화를 통해 층 사이의 입출력 값의 분포가 일정해지면 학습이 안정화된다.
Internal Covariate Shift
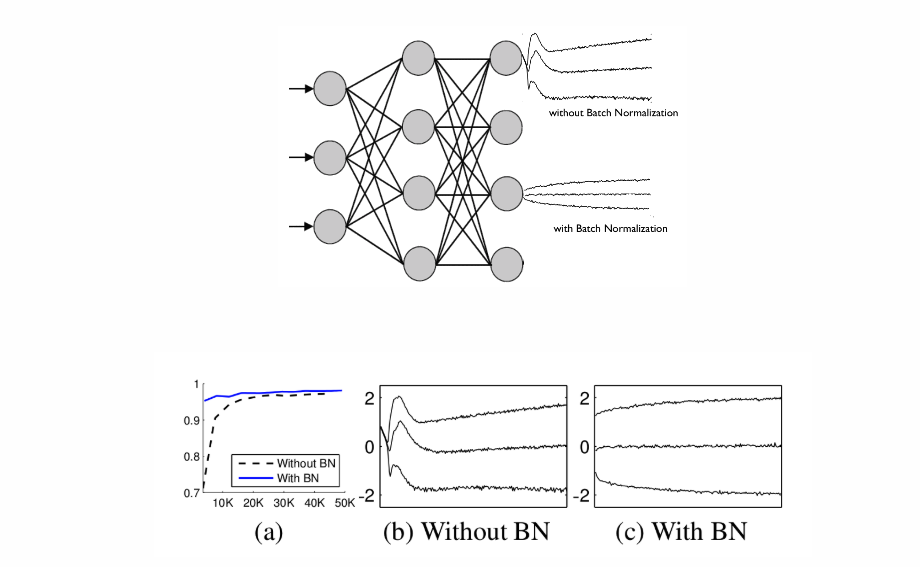
Internal covariate shift는 이전 레이어의 파라미터들의 값이 바뀜에 따라 이후 레이어의 입력 분포가 바뀌는 것을 말하고, 이로 인해 학습 시 불안정성이 증가한다. 불안정성을 줄이기 위해 출력을 평균 0, 분산 1로 정규화시키는 Whitening이라는 방법을 생각해볼 수 있다. 하지만,
층의 수가 매우 많은 신경망에서는 이 계산 과정이 복잡하다.
활성화 함수의 비선형성이 발생하는 지점이 일정하게 고정된다.
정규화는 평균을 일정하게 0으로 만들기 때문에 각 뉴런의 학습된 bias가 무시될 수 있다.
고정된 형태의 정규화로 인해 입력 분포의 중요한 특성이 강제로 재배열될 수 있디다.
Batch Normalization
Whitening의 단점을 상쇄하기 위해 Batch Normalization은 정규화 과정을 별도의 것으로 간주하지 않고 학습 과정에 포함시킨다.
평균 계산
: Mini-Batch 내의 모든 데이터들의 평균을 계산한다.
분산 계산
: Mini-Batch 내의 모든 데이터들의 분산을 계산한다.
Normalization
: 위에서 구한 수치들을 이용해 데이터의 정규화를 진행한다. (평균 0, 분산 1)
Linear Transformation (Scale & Shift)
: 정규화된 결과에 학습 가능한 파라미터인 를 추가한다.
Scale & Shift는 이전처럼 고정된 형태가 아닌, 학습 가능한 선형 변환이기 때문에 입력 분포를 해치지 않고, 활성화 함수의 비선형성을 보존할 수 있다. 결국 학습 가능한 파라미터를 추가해줌으로써 학습을 돕기 위해 분포를 안정화시키되, 그 분포의 최종 형태는 모델이 결정하는 것이다.
정리하자면,
각 층의 입력 분포가 고정되어 안정된 학습 가능
학습률을 크게 설정해도 안정적인 학습 가능
정규화로 인해 Loss landscape가 평탄화되어 local minimum에 빠질 가능성 감소
정규화와 학습이 함께 진행되어 속도가 빠름
BatchNorm at Inference Time
Batch Normalization은 훈련 중 각 mini-batch에서 평균과 분산을 계산하여 정규화를 수행한다. 그러나 테스트 시에는 이 batch 평균과 분산을 그대로 사용할 수 없기 때문에, 전체 데이터셋에 대한 대표값으로 moving average 를 학습 중에 지속적으로 추적해 저장해둔다.
Practical Aspects
훈련 시 얻은 통계량을 저장해 사용
테스트(추론) 시에는 훈련 도중 저장해 둔 moving average 통계치를 사용한다. 테스트 시에는 batch의 통계량을 알 수 없기 때문이다.
BN 을 네트워크 내에 적용하는 횟수
매 레이어마다 넣는 방법과 간격을 두고 넣는 방법이 존재한다. 이는 Hyperparameter 이며, 모델의 구조와 데이터 특성에 따라 다르게 설정된다.
BN 이 항상 도움되는 것은 아니다.
BN 이 어디에 와야 할까?
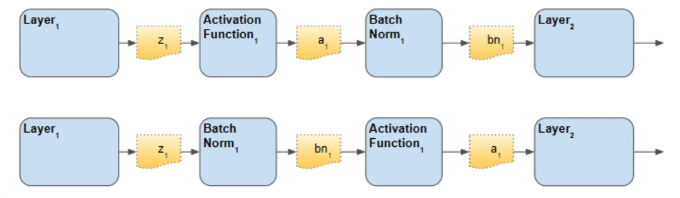
Activation 이후에 적용하는 것이 성능이 좋다는 말이 많다.
BatchNorm in CNN
CNN에서 하나의 채널은 하나의 feature detector를 의미한다. 이를 유지하기 위해 CNN에서 BatchNorm을 적용할 때는 각 채널을 기준으로 통계량을 계산하고, Scale & Shift를 적용하게 된다.
LayerNorm
LayerNorm은 배치 단위가 아닌 하나의 샘플 안에서 feature 차원 전체의 평균과 분산을 계산해 정규화하는 방법이다. 배치 차원을 사용하지 않고 각 샘플을 독립적으로 정규화한다.
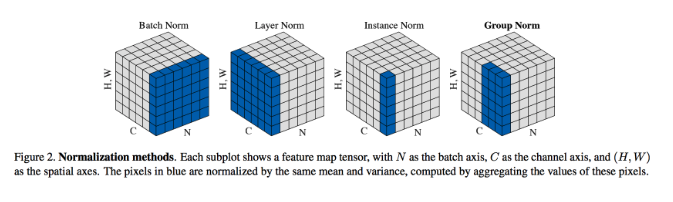
BatchNorm vs LayerNorm
전통적인 CNN 계열에서는 BatchNorm을, Transformer 계열에서는 LayerNorm이 표준이다. Vision, Language 도메인의 차이라기보단 모델의 구조적 차이를 통해 이해해야 한다.
CNN & BatchNorm
CNN에서 하나의 채널은 하나의 feature detector로, 같은 채널의 값들은 같은 위치의 정보를 나타낸다. 배치 내 샘플들 간 채널 방향의 정규화는 CNN의 inductive bias와 잘 맞아 떨어진다. 또한 CNN은 메모리 소모량이 적어 큰 배치 크기를 사용할 수 있어 BatchNorm 통계가 안정적이다.
Transformer & LayerNorm
Transformer의 경우에는 이야기가 다르다. 서로 다른 토큰들은 상이한 정보를 담는다. 배치 기준의 BatchNorm을 사용하게 되면 의미가 다른 토큰들의 분포가 섞이게 된다. 또한 Transformer는 CNN과 달리 메모리 소모가 커 큰 배치 크기를 사용하기 쉽지 않아 BatchNorm 통계가 불안정적이다. Transformer의 입력 시퀀스의 길이는 가변적이기 때문에 분포 변화가 커 학습 상황과 추론 상황의 통계량 불일치 가능성이 크다는 것도 문제다. 그렇기 때문에 Transformer 구조에서는 각 샘플별로 embedding dimension에 대해 정규화를 하는 LayerNorm이 더 적합하다.
ViT에서도 마찬가지이다. CNN처럼 vision 도메인이지만, transformer 구조를 사용하기 때문에 LayerNorm이 적합하다.