Embeddings
언어 모델들은 문장을 토큰이라는 단위로 쪼갠 후, 각 토큰에 임베딩이라는 것을 적용한다. 임베딩이라는 것은 단어의 의미를 담은 벡터를 생성해 특징 공간에 매핑하는 행위를 말한다.
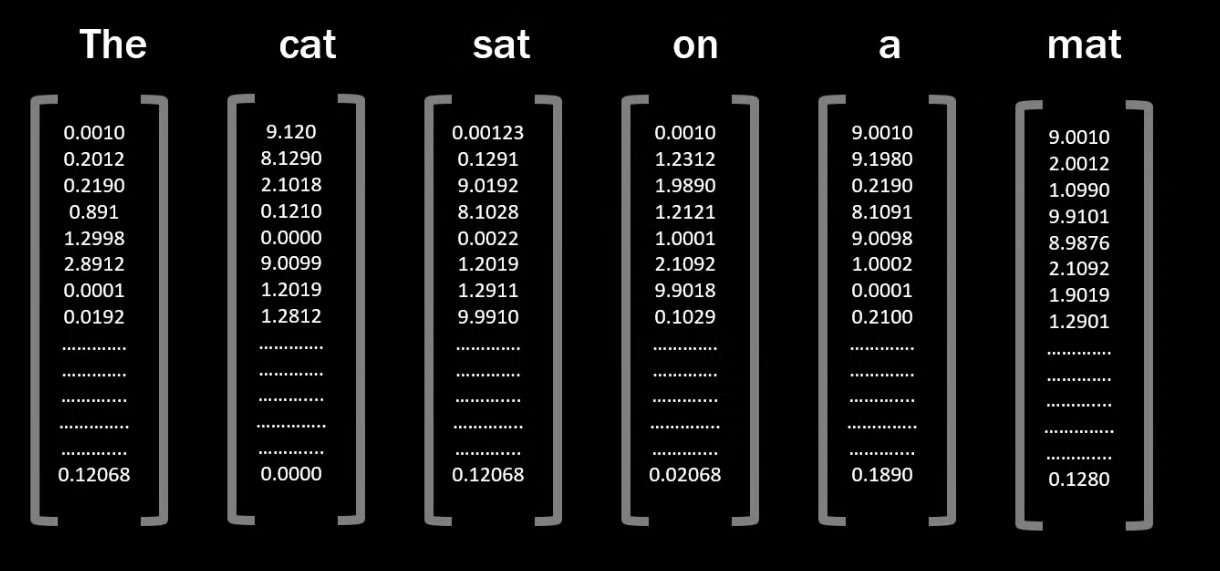
임베딩에는 학습된 임베딩 행렬이 이용되는데, 이 행렬의 차원은 (total vocab size x embedding dimension)으로, lookup table과 같은 역할을 한다. 의미가 비슷한 단어일수록 벡터 공간에서 거리가 가깝게 위치한다.
이렇게 입력 단계 전에 미리 학습되어 고정된 임베딩 행렬을 이용해 임베딩을 하는 방식을 static embedding이라고 한다. 하지만 이 방식은 동음이의어처럼 문맥에 따라 여러 의미를 가지는 단어를 처리하는 데에서 한계가 발생한다. 임베딩 행렬은 한 단어당 하나의 임베딩 벡터를 부여하기 때문에 이런 일이 발생하는 것이다.
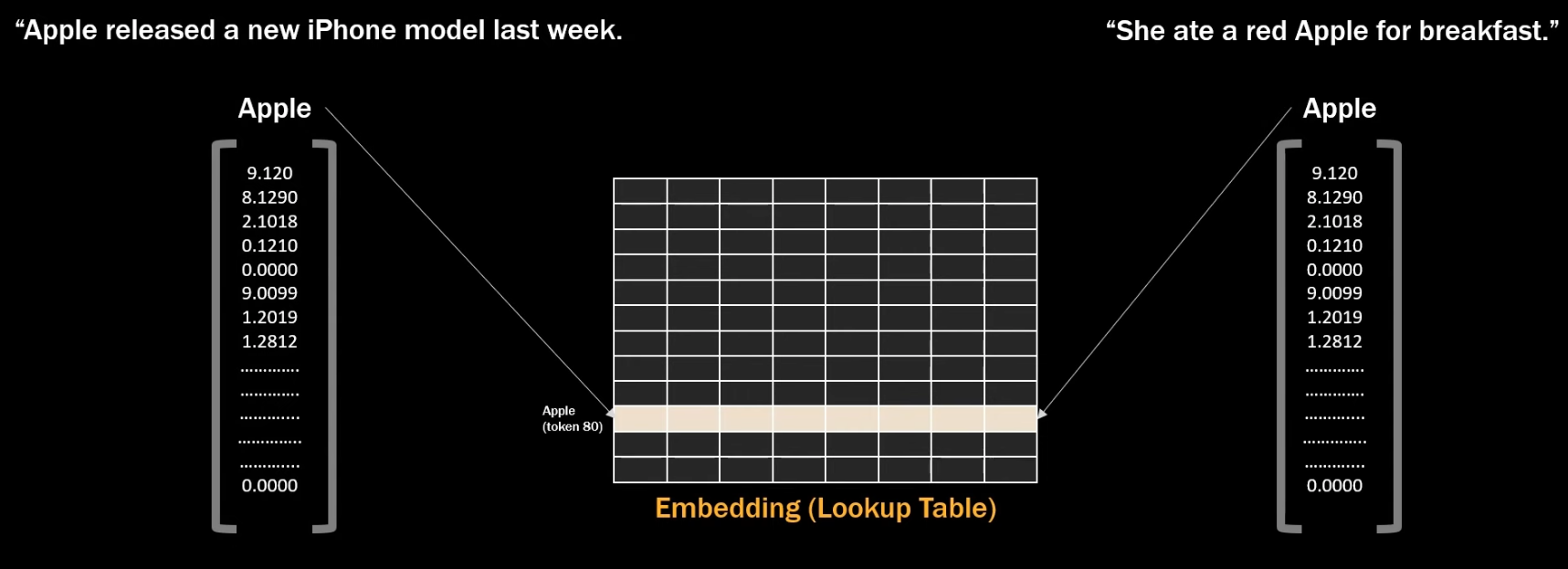
이런 한계를 해결하기 위해 문맥적 특징을 고려할 수 있는 방식이 필요하게 되었다.
Self Attention
Self Attention은 각 토큰이 문장 내의 다른 모든 토큰을 참조하여, 현재 토큰 표현을 문맥에 맞게 재계산하는 메커니즘이다. 이렇게 생선된 새로운 표현을 Contextual Embedding이라고 한다. Self Attention의 수식은 아래와 같다.
이 수식을 이해하기 위해서는 Q(query), K(key), V(value)가 무엇인지 알아야 한다.
Query, Key, Value

한 토큰의 임베딩 벡터에 세 개의 learnable한 선형 변환이 적용되어 Query, Key, Value 벡터가 생성된다. Query는 한 토큰이 문맥 속에서 어떤 정보를 필요로 하는지 나타내는 벡터다. Key는 한 토큰이 어떤 정보를 가지는지 나타내는 벡터다.
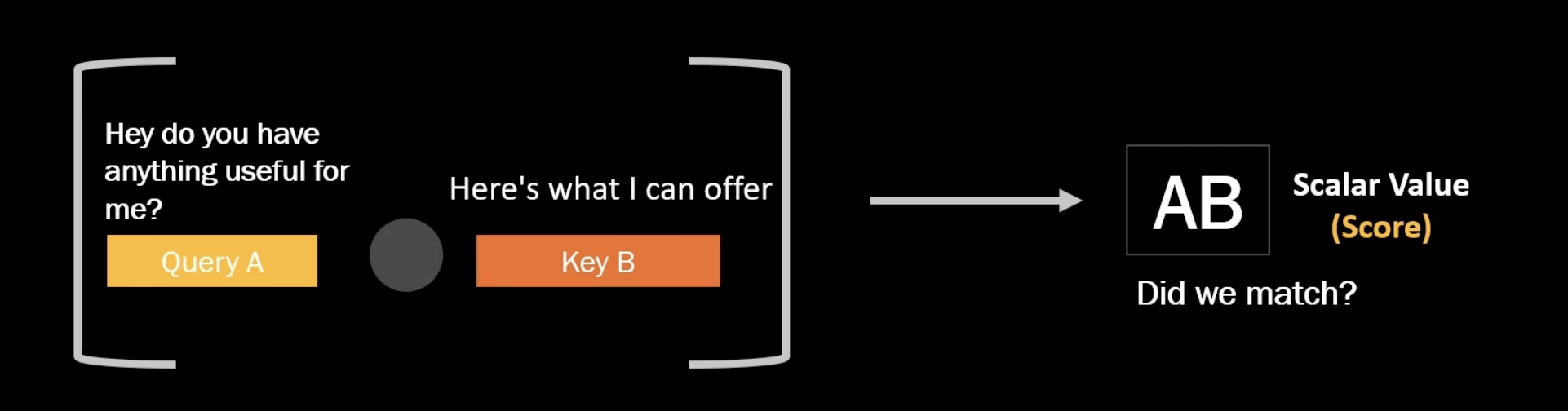
토큰 A의 Query가 다른 모든 토큰들의 Key와 내적을 거치면, Attention Score라는 스칼라 값이 도출된다. 이는 두 토큰 A와 B가 얼마나 관계되어 있는지 나타내고, softmax를 통해 가중치인 attention weight으로 변경된다. softmax 적용 전 로 나누어 scaling을 거친다.
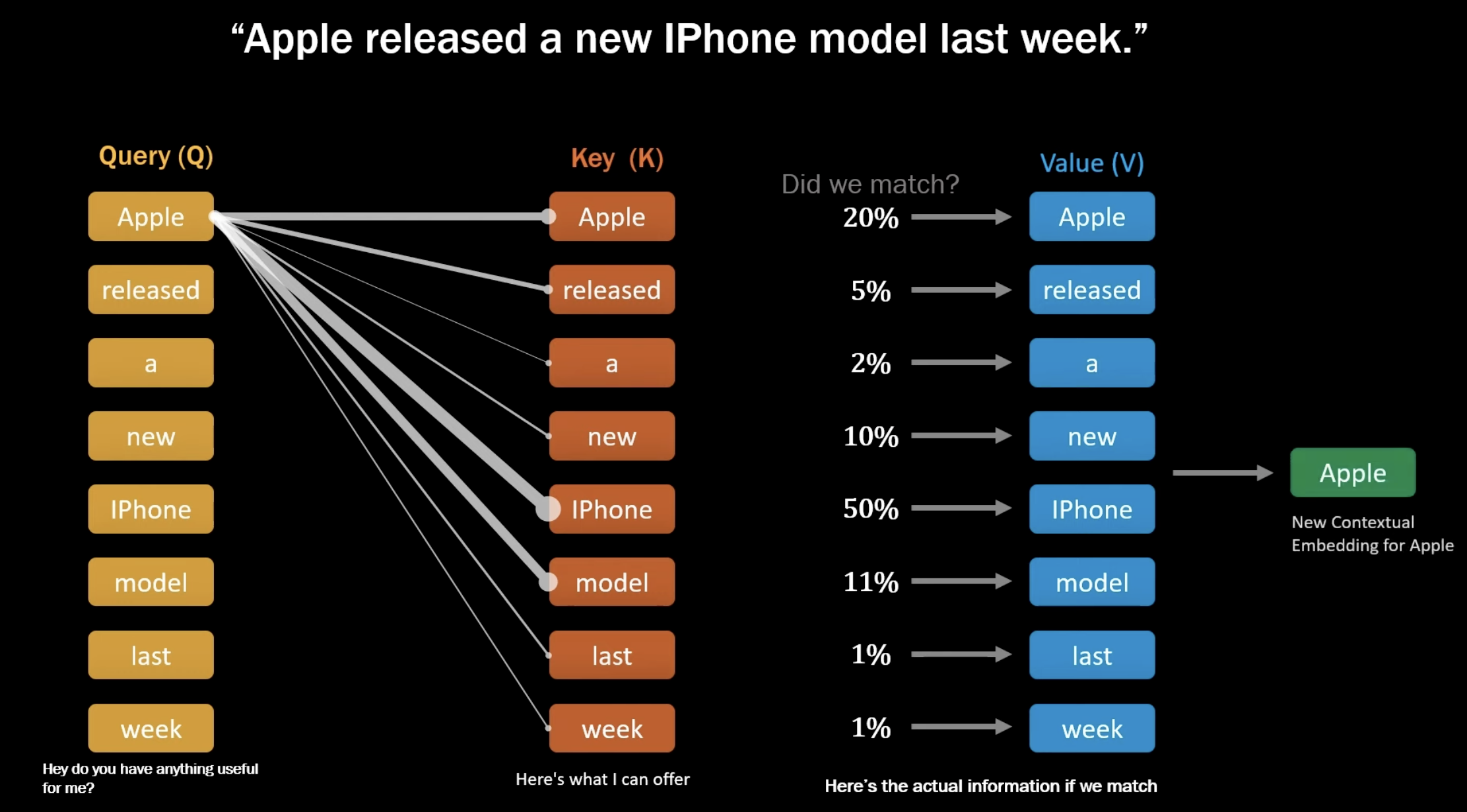
Representation 형성에는 Attention Score와 함께 Value가 사용된다. Value는 실제 문맥 정보를 구성할 때 사용되는 의미를 담은 벡터다. Attention score는 Value에 직접 곱해지고, Attention weight에 기반한 가중합으로 문맥을 고려한 새로운 Representation이 생성되는 것이다.