Introduction
Transformer의 등장으로 100B에 육박하는 파라미터들을 가지는 LLM들을 대규모 데이터셋으로 훈련할 수 있게 되었다. 이를 본받아 컴퓨터 비전 영역에서도 CNN 구조를 self-attention으로 대체하려는 시도들이 있었다. 하지만 이론상으로 효율적이라고 알려진 이 방식이 실제의 하드웨어에서는 효과적으로 병렬 처리가 되지 못했다. 이는 특수한 형태의 attention이 사용되었기 때문이다.
이를 개선하기 위해 이 논문에서는 일반적인 transformer에 최소한의 수정을 거쳐 이미지 데이터를 적용한다. 이 과정에서 이미지는 patch 단위로 분할되고, 각 patch에 대한 embedding vector가 생성된다. 이 벡터들이 transformer의 입력이 되고, LLM에서의 token과 같은 역할을 하게 된다. 이렇게 이미지 데이터를 입력받을 수 있게 수정된 구조를 ViT(Vision Transformer)라고 한다.
ViT는 CNN 구조에 비해 inductive bias가 적다. Inductive bias란 모델이 입력 데이터에 대해 가지고 있는 가정이나 추측을 말한다. CNN 구조는 입력 데이터에 locality와 translation equivalence가 존재할 것이라는 inductive bias를 가지는 것이다. 이로 인해 ViT는 중소 규모의 데이터셋을 훈련했을 때는 ResNet 구조에 비해 성능이 다소 떨어진다. 하지만 ViT의 진가는 천만~억 단위의 대규모 데이터셋을 훈련했을 때 발휘된다. Transformer의 병렬 처리 능력을 활용해 14M~300M 장의 이미지에 대해 사전학습된 후, downstream task에 대해 fine-tune된 ViT는 ResNet의 성능을 훨씬 능가한다.
Related Work
Transformer에 대한 내용은 아래를 참고하자.
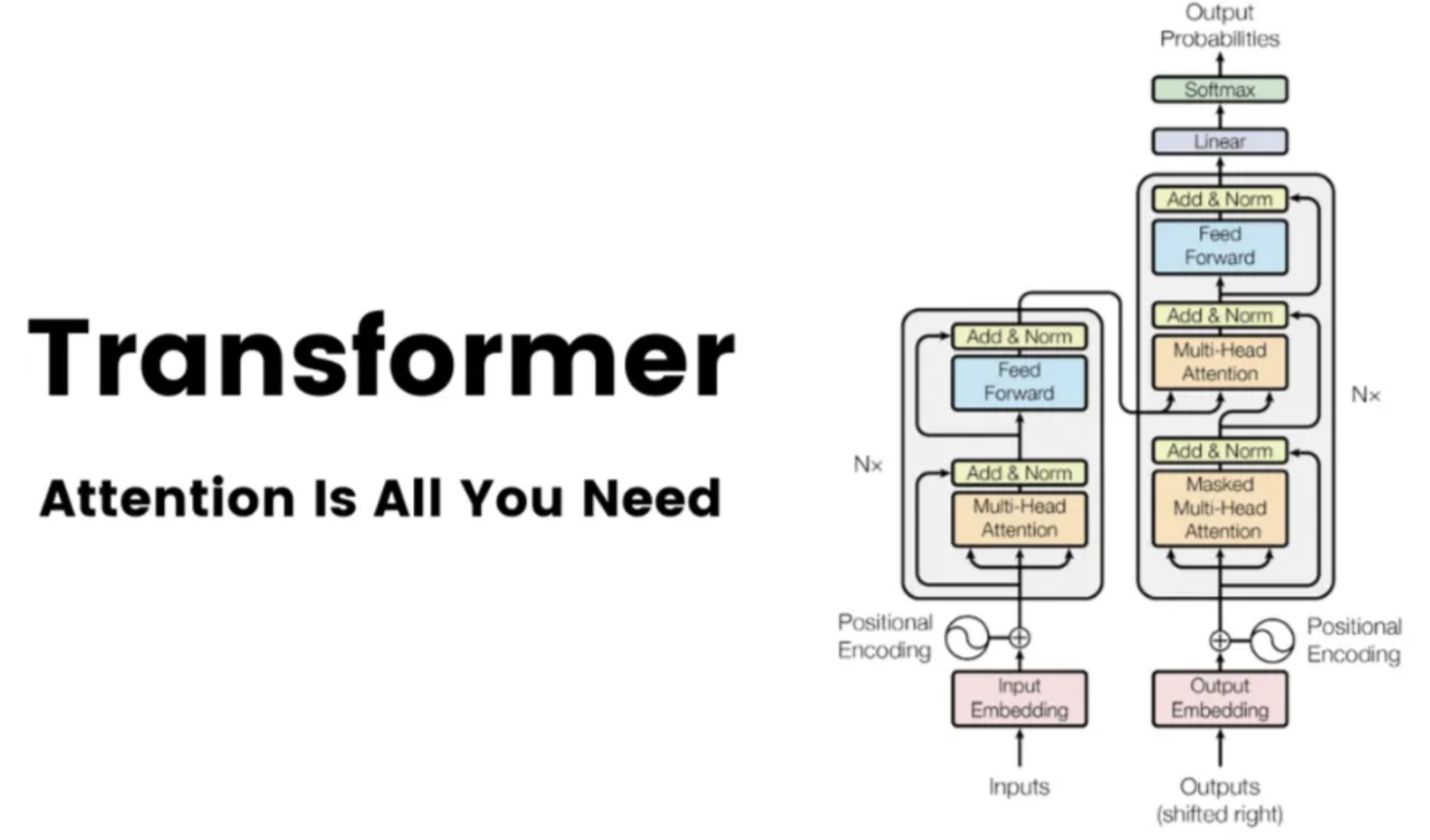
ViT의 구조는 아래 논문에서 영감을 많이 받았다고 한다.
이미지에 순수하게 self-attention을 적용하는 것은 한 픽셀이 다른 모든 픽셀들을 참고하게 될 것인데, self-attention은 의 복잡도를 가지기 때문에 현실적인 input size에 부합하지 않을 것이다. 위 논문에서는 이를 개선하기 위해 픽셀 단위가 아닌 2x2 크기의 patch로 이미지를 분할한 후 self-attention을 수행한다.
하지만 이 방법으로도 저해상도 이미지에만 적용점이 국한된다는 한계가 있다. ViT는 중해상도 이미지를 다룰 수 있다는 점, Vanilla Transformer 구조를 차용해 기존의 SotA CNN보다 더 좋은 성능을 증명해냈다는 점에서 해당 연구보다 우위를 점한다.
Methods
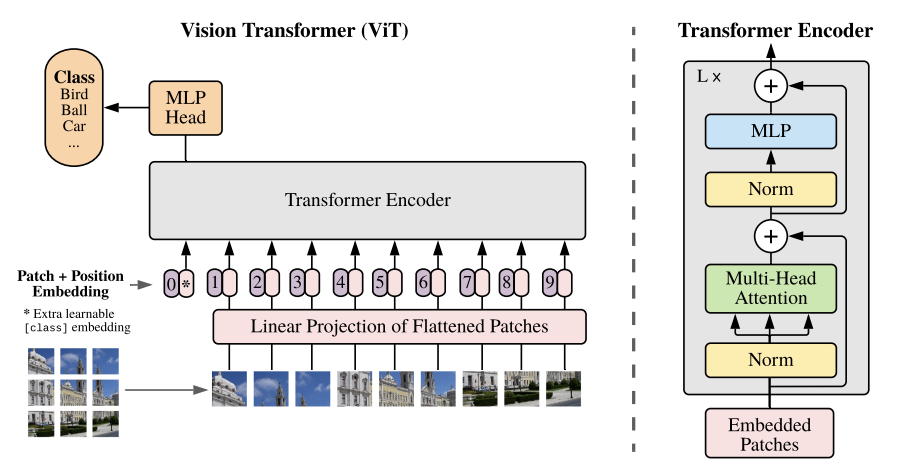
상술했듯이 기존의 Transformer의 구조를 최대한 그대로 채용해 구현의 효율성을 챙긴다.
ViT (Vision Transformer)
기존의 transformer는 token embedding들의 sequence 즉 1차원 데이터를 입력 받았다. 이미지와 같이 2차원 데이터를 입력받기 위해 이미지 를 patch들의 sequence로 reshape한다.
여기서 는 hyperparameter이다.
Transformer에서는 layer 전체에서 공통된 길이()의 벡터들을 사용했다. 이를 똑같이 적용하기 위해 patch들을 flatten한 후 linear projection을 통해 차원의 벡터로 변환해준다.
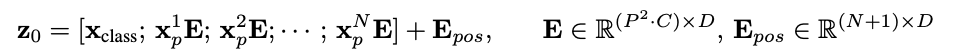
은 ViT의 인코더에 입력되는 초기 입력 시퀀스다. 표기는 concatenation을 의미한다.
여기서 등장하는 는 CLS token이라고 불리는 classification을 위한 특별한 token이다. BERT의 [class] token과 유사하게 전체 이미지 정보를 모으는 대표 벡터 역할을 한다. 는 learnable하다.
는 learnable한 position embedding 행렬로, 각 토큰의 위치 정보를 더해주는 역할을 한다.
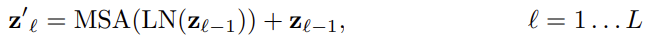
다음으로 Transformer의 동작에 관한 식이다. 입력 값에 Layer Norm을 적용한 후 Multi Head Attention 층을 거진다. 출력값에는 Residual Connection이 적용된다.

Transformer의 출력은 MLP로 이루어진 classification head를 거친다. 구조는 다음과 같다.
Training Time: MLP with one hidden layer
Fine-Tuning Time: Single linear layer
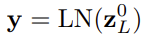
마지막으로 cls token에 Layer Norm이 적용된 것이 해당 층에서의 image representation의 역할을 한다.
Transformer Encoder
ViT에서 사용되는 인코더는 multi-head self attention 층과 MLP 층이 번갈아가며 나타나는 구조를 가진다. 모든 층 이전에는 LayerNorm이 적용되고, 출력에는 Residual Connection이 적용된다.
MLP는 두 개의 linear layer와 사이에 GELU 활성화 함수로 구성된다.
Fine-Tuning and Higher Resolution
특정 task에 대한 성능을 증대시키기 위해서는 ImageNet과 같은 대규모 데이터셋에 대해 ViT를 사전학습시킨 후, downstream task에 맞게 fine-tuning을 진행하는 방식을 사용한다. 이를 위해서는 기존의 prediction head를 제고하고, zero-initialized feed forward network을 추가한다. 여기서 는 downstream class에서 사용되는 클래스의 갯수를 의미한다.
Fine-tuning 시에 pretraining에 이용한 해상도보다 높은 해상도의 이미지를 이용하는 것이 유리한 경우가 많다. 하지만 해상도가 달라진다고 해서 patch의 크기를 변화시키지는 않는다. 이로 인해 입력 시퀀스의 길이가 더 길어지게 되고, pretrained position embedding이 의미를 잃게 된다. 이를 방지하기 위해 변화한 시퀀스 길이에 맞춰 position embedding의 결과에 2D interpolation을 수행해 위치를 맞춰준다.
Inductive Bias
상술했듯이 ViT는 CNN 구조보다 훨씬 적은 inductive bias를 가진다. CNN이 가지는 inductive bias는 다음과 같다.
Locality
이미지에서 인접한 픽셀들이 더 강한 상관관계를 가진다는 가정이다. 이런 가정 하에 CNN은 원본 이미지보다 작은 receptive field를 가지는 kernel을 사용해 국소적인 특징을 추출하는 것이다.
Weight Sharing
동일한 가중치를 가지는 kernel이 위치에 상관없이 사용된다. 공간적 위치와 무관하게 특정한 특징은 동일한 방식으로 탐지할 수 있다는 가정을 가지는 것이다.
Hierarchical Composition
국소적인 낮은 semantic level에서는 국소적인 특징이, 높은 semantic level에서는 전역적인 특징이 추출된다고 여겨진다. 높은 semantic level의 feature map은 낮은 level에서의 feature map의 성분들의 linear composition을 통해 생성된다. 즉, 복잡한 시각 정보가 단순한 패턴들의 조합으로 구성된다는 가정을 가지는 것이다.
Translation Equivariance
Convolution 연산의 입력에 평행 이동을 적용하면, 출력에도 동일한 평행 이동이 적용된다. 이는 CNN이 위치 변화에 강인해지도록 만들어주는 inductive bias다. 이 특성은 locality와 weight sharing에서 귀결되는 성질이다.
이와 반대로 ViT는 global context를 이용하는 self-attention을 쓰고, 이외의 inductive bias도 가지지 않는다. ViT에서 유일하게 inductive bias가 적용되는 부분은 positional encoding 적용 시점에서의 locality다.
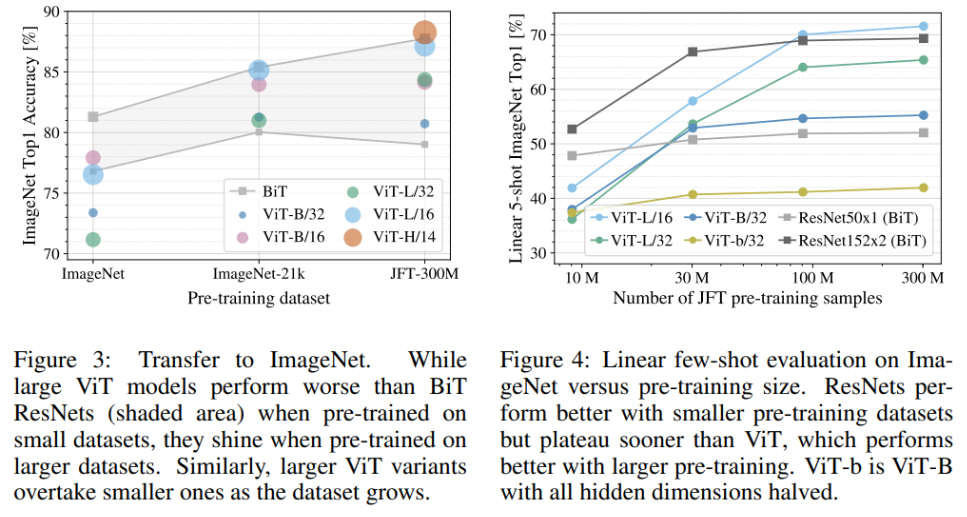
이런 차이로 인해 ResNet에 비해 비교적 작은 데이터셋에서는 성능이 밀리지만, 데이터셋의 크기가 커질수록 ViT가 성능 면에서 우월해지는 것을 볼 수 있다. ViT는 ResNet에 비해 데이터의 scalability 측면에서 우수한 것이다.
Conclusion
ViT는 transformer encoder를 거의 그대로 차용해 이미지 특징 추출에서 좋은 성능을 냈다. 동시에 기존 CNN 계열 모델들보다 computational cost도 적다.