[Meta Research] V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Introduction
World Models
월드 모델(World Model)이란 sensory data를 통해 세상의 물리적 법칙과 현상을 이해하는 모델로, 환경의 transition dynamics를 추상적 latent space에 모델링할 수 있다. 월드 모델과 함께 동작을 설계하는 planner를 이용하면 세상의 물리적 법칙을 동작 설계에 일관되게 적용하는 physical consistency를 이룰 수 있다.
기존의 방법들은 월드모델과 강화학습을 사용해 자신의 동작을 설계했다. State action pair를 이용해 환경과 상호작용하고, 그로부터 도출되는 명시적인 보상 피드백을 통해 동작을 학습한다. 하지만 이런 방식은 환경과의 상호작용이 강요되고, 실제 환경에서 강화 학습을 위한 데이터 수집은 비용이 매우 높다는 한계가 있다.
Learning the World by Videos
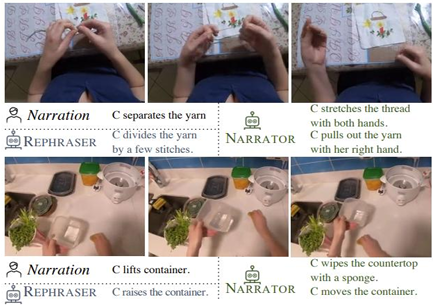
데이터 수집의 어려움을 타파하기 위해 sensory data가 풍부한 비디오 데이터를 이용하는 시도들이 등장했다. 비디오 데이터에는 action label이 없기 때문에 training signal을 얻기 위해 텍스트 주석을 사용했다. 하지만 텍스트 주석은 추상적인 설명 위주로, 구체적인 동작이나 물리적 변화를 표현하는 데 한계가 있었다. 이로 인해 비디오 속 주체의 다음 상태에 대한 예측이 어려웠다.
V-JEPA 2
이 논문에서 소개하는 V-JEPA2는 비디오 자체에 대한 representation learning을 통해 미래의 프레임의 representation을 예측한다. 기존 방식들과 다르게 state action pair, reward, text caption 모두 불필요하다. 또한 인간이 내재된 world model을 학습하는 방식과 가장 유사하다고 평가된다.
Preliminaries
Joint Embedding Predictive Architecture (JEPA)
V-JEPA 2의 기초가 되는 video representation learning을 위한 구조다. Label 없이 데이터 자체에서 training signal을 얻는 self-supervised learning(SSL)을 이용한다.
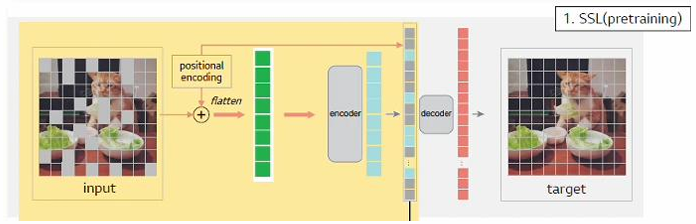
기존의 SSL 방식은 masked autoencoder와 유사하게, 이미지에 마스킹을 적용한 후 가려진 부분의 픽셀 값을 예측하는 방식으로 훈련했다. 하지만 픽셀 단위의 예측을 하다 보니, 상대적으로 낮은 semanitc level의 representation을 학습해 downstream task에서의 성능이 좋지 않았다.
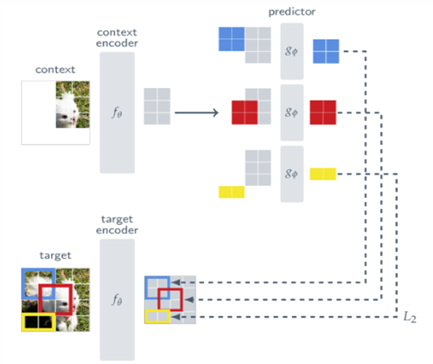
JEPA는 pixel 단위의 예측 대신 representation space에서의 예측을 진행해 이를 해결한다. 가려진 부분의 픽셀 값이 아닌, 한 frame 전체의 representation을 예측하는 것이다.
학습 과정은 아래와 같다.
입력 이미지의 일부에 random masking 적용 (남은 부분이 context)
context encoder가 context의 representation 생성
predictor가 unseen representation 예측
target encoder가 ground truth인 전체 이미지의 representation 생성
representation간 L2 loss를 통해 optimization
이 때 target encoder의 가중치는 learnable하지 않고, context encoder의 EMA(Exponential Moving Average)로 설정된다.
V-JEPA2: Scaling Self-Supervised Video Pretraining
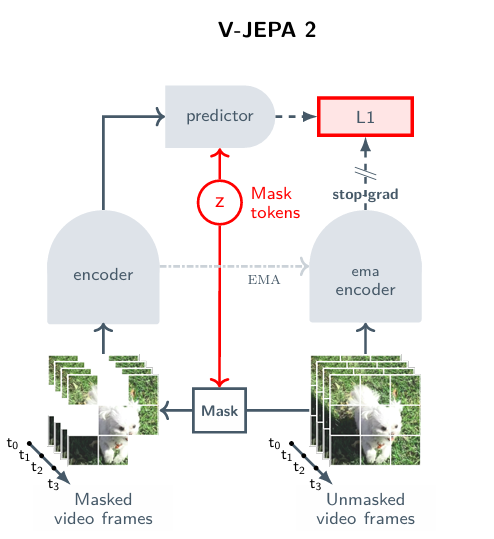
JEPA 구조를 기반으로 비디오 프레임의 representation을 학습하는 과정이다.
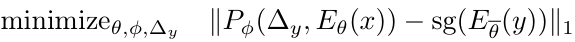
여기서 는 마스크의 위치를 알려주는 learnable mask token이다. 비디오에는 3D-RopE라는 3차원 시공간 positional embedding이 적용된다.
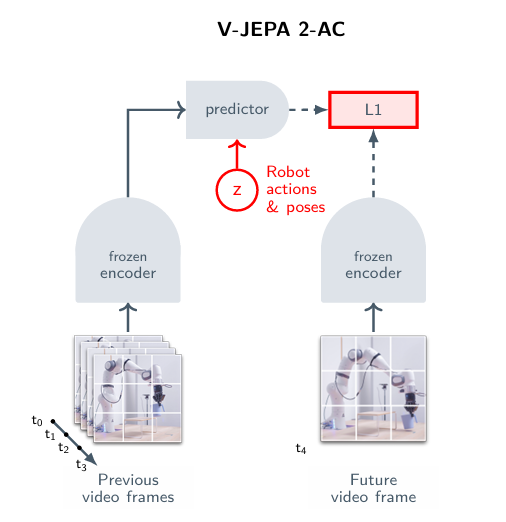
V-JEPA2 AC: Learning an Action-Conditioned World Model
Action Conditioned World Model Training
V JEPA-2는 사전 학습을 통해 비디오 프레임의 representation learning을 진행했다. 하지만 한 프레임의 정보만으로는 영상 속 주체가 어떤 행동을 할 예정인지, 그리고 그 행동이 미래에 어떤 영향을 끼칠지는 알 수 없다. 이를 해결하고 world model을 얻기 위해, 약간의 상호작용 데이터를 이용해 V-JEPA2 AC라고 불리는 action conditioned model을 훈련시킨다. 사전 학습 단계에서 훈련시킨 인코더의 가중치를 고정시킨 후, 다음 프레임의 representation을 예측하는 predictor를 학습시킨다.
Model Inputs
훈련 데이터는 DROID 데이터셋에서 얻은 62시간의 unlabed video를 이용한다. 동영상에서 등장하는 로봇은 7-DoF Franka이고, two-finger gripper와 단안 외장 카메라를 사용한다. 학습에는 어떠한 텍스트나 보상, 성공 여부 데이터가 쓰이지 않고, 동영상과 7차원 벡터인 end effector state만이 이용된다.
훈련 과정의 각 iteration마다 4초 길이의 영상들로 이루어진 batch를 형성한다. 각 영상은 4fps로 샘플링되어 256 x 256 x 16 의 차원을 가진다. 한 비디오의 각 프레임은 , 해당 시점의 end-effector state는 로 표현된다. 각 프레임 사이에서 행해지는 행동 는 해당 시점과 다음 시점의 end-effector state의 변화로 정의된다.
Loss Function
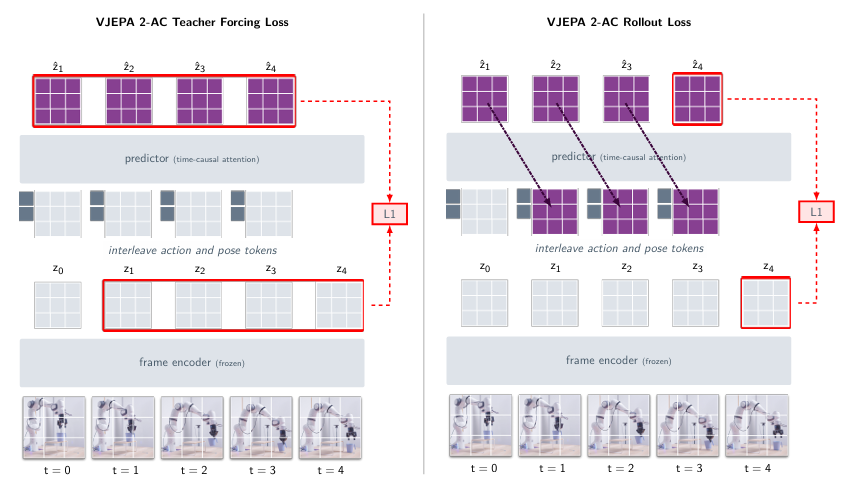
두 가지 loss function이 사용된다. 첫 번째는 바로 다음 프레임의 representation을 예측하는 것을 학습하기 위한 teacher-forcing loss다.
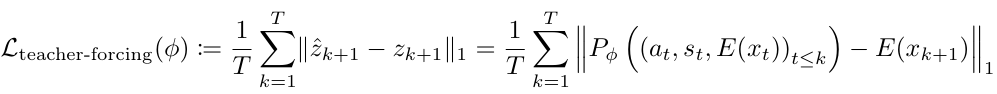
한 프레임의 가 인코더에 입력되면, 다음 프레임 representation의 예측값인 이 출력되고, 이를 학습하기 위함이다. 각 프레임에서 예측값과 실제 representation 사이의 L1-loss의 평균이 loss로 사용된다.
추론 시간에서 V-JEPA 2 AC는 자신이 예측한 representation을 입력으로 해 그 다음 예측을 진행하는 auto-regressive한 추론을 진행한다. Teacher forcing loss 계산 시 입력은 데이터셋에서 온 실제 값이기 때문에, 실제 값 없이 추론하는 능력을 기르기 위해 rollout loss를 사용한다.
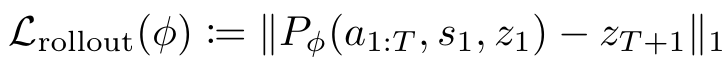
처음부터 T개의 action으로 이루어진 action sequence와 을 초기 입력으로 사용한다. action sequence에서 얻은 action과 각 시점에서 예측한 representation을 입력으로 해 auto regressive한 방식으로 시점의 representation을 예측한다. 이 예측값과 실제 값 사이의 L1-loss 가 rollout loss로 쓰인다. 논문에서는 로 설정하는데, 더 큰 값 사용 시 연산량이 부담스럽기 때문이다. 결국 rollout loss 계산 시에는 모든 프레임을 다 사용하는 것은 아니게 된다.
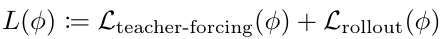
전체 loss는 두 손실 함수의 합으로 정의된다.
Architecture
Predictor network은 300M 파라미터 규모의 transformer network이다. 24개의 레이어, 16개의 head, 1024 hidden dimensions, 그리고 GELU activation을 사용한다.
영상이 인코더에 입력되기 전에 각 patch의 시공간 정보를 표시하기 위해 3D-RoPE라는 positional embedding이 적용된다. 반면 action과 pose token에는 시간 정보만 표시하면 되기 때문에 temporal RoPE가 적용된다.
입력값인 각 시점의 action, state, flattened feature map은 learnable한 affine 변환을 통해 predictior의 입력 차원과 맞춰진다. 이와 비슷하게 predictor의 출력도 L1 loss 계산을 위해 learnable affine transformation을 통해 인코더의 embedding 차원과 맞춰진다. 여기서 행해지는 attention 연산은 block casual attention이라고 불리는데, k 시점의 patch feature은 이전 시점까지의 모든 정보에 접근할 수 있지만, 미래 시점의 정보는 접근할 수 없음을 뜻한다.
Inferring Actions by Planning
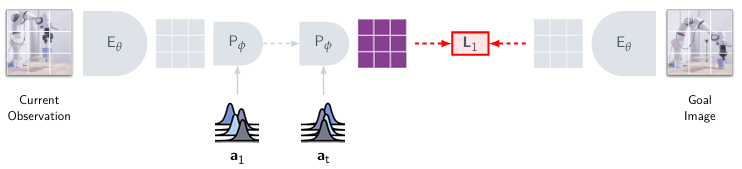
로봇에게 목표 이미지가 주어지면, 시스템은 V-JEPA 2 AC를 활용해 적절한 action sequence를 계획한다. 이 때의 목표는 현재 상태에서 목표 상태까지 도달할 수 있도록 일정한 planning horizon 동안의 action sequence를 아래와 같은 energy function을 최소화하는 방식으로 최적화하는 것이다.
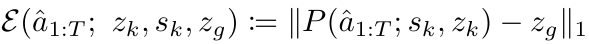
Optimization은 gradient descent가 아닌 Cross Entropy Method(CEM)이 사용된다.
각 step의 action들은 가우스 분포를 따른다고 가정하고, 무작위로 action을 샘플링
샘플링을 통해 얻은 action sequence를 world model에 입력해 미래 representation을 예측
goal representation과의 energy가 낮은 top K개의 sequence 선택 (elite set)
elite set의 평균, 분산값을 이용해 새로운 가우스 분포를 생성
1~4를 평균과 분산이 수렴할 때까지 반복
이렇게 얻어낸 최적의 action sequence의 첫 action을 실제로 수행하고, 새로운 상태인 를 반복한다. 결론적으로, V-JEPA2 AC라는 월드 모델이 내부적으로 학습한 물리적 일관성(physical consistency)를 이용하여 CEM이라는 planner가 action sequence를 최적화하는 것이다.
Limitations
카메라 위치 민감도
명시적인 카메라 보정 없이 단안 RGB 카메라 입력만을 이용하기 때문에 추론된 좌표축이 카메라 위치에 만감하게 반응한다. 이로 인해 오류가 발생할 여지가 있다.
장기 계획의 어려움
V-JEPA 2 AC는 auto regressive한 예측을 하는데, 이는 오차의 누적으로 인해 장기적인 계획에 불리할 수 있다. Pick and place와 같은 복잡한 과제를 위해서는 개선이 필요하다.
시각적 목표 의존성
목표의 representation 에 근접하도록 학습하기 때문에 시각적 특징 기반 제어만 가능하다는 한계가 있다. 향후 언어 기반 제어를 위해 텍스트와 representation space 에서의 alignment 가 필요하다.