[ICML 2021] Learning Transferable Visual Models From Natural Language Supervision
이전까지의 Computer Vision 모델들은 고정된 카테고리 내의 객체들을 구별하는 방식으로 훈련되었다. 이런 방식은 모델의 일반화 능력을 학습된 카테고리에 국한시킨다. 학습 내용 외의 시각적 특성(unseen visual concepts)를 인식하기 위해서는 추가로 라벨링된 데이터가 필요하기 때문에 확장성이 좋지 않다.
대신 이미지 캡션과 같은 raw text를 학습에 이용하면, 일일히 labeling을 해줄 필요도 없을 뿐더러 이미지에 대한 의미적 정보를 더 폭넓게 제공받을 수 있다. 여기서 착안해 이 논문에서는 이미지에 어떤 캡션이 올지 예측하는 것은 기존의 방식보다 더 scalable하고 효과적이라고 주장한다. 4억개의 (image, text)쌍에 대해 사전 학습을 거친 후, downstream task에 대한 fine-tuning을 진행하는 형식으로 모델을 적용한다.
이 방법론을 사용한 모델은 추가적인 학습 없이(zero-shot) 특정 태스크를 위해 추가적인 데이터셋으로 학습한 기존 모델들과 견줄만한 성능을 낼 수 있었다.
Introduction
NLP에서는 task-agnostic(특정 작업에 국한되지 않는) 방법들이 대규모 데이터셋에서 좋은 성능을 보였다. 이런 방법들에는 입력 시퀀스의 다음에 위치할 토큰을 예측하는 autoregressive 방식이나 입력 시퀀스의 일부를 가린 후 복원하는 masked language modeling 등이 있다. 이들은 특히 특정 task를 위한 output head나 dataset customizing 없이도 downstream task로의 zero-shot transfer이 가능했다. 좋은 예시로는 하나의 모델로 여러 task를 처리하는 GPT-3가 있다.
이것이 가능하게 된 원인으로는 웹으로부터 수집된 대규모 비구조적 언어 데이터가 과거의 정제된 라벨 데이터보다 더 풍부한 학습 신호를 주기 때문으로 평가된다. 즉 supervision(의미적 정보)의 양적, 질적 향상이 발생한 것이다. 이 논문은 이 점에 집중해, 이것이 Vision task으로도 확장이 가능할지 의문을 던진다. 이전까지 Vision은 여전히 ImageNet 같은 crowd-labeled dataset에 의존하는 task-specific pretraining 단계에 머물러 있었기 때문이다.
이전의 연구들은 인스타그램에서 수집한 대규모 이미지-해시태그 데이터를 이용해 weak-supervision 방식으로 학습을 수행했다. Weak-supervision은 라벨링이 어려운 상황에서 노이즈가 있거나 일부 부정확한 소스인 weak label을 이용하는 방식이다.

이들은 학습할 수 있는 클래스의 갯수가 제한적이었고, static softmax classifier를 사용했기 때문에 동적인 output을 생성할 수 없었다. 이로 인해 zero-shot generalization 능력이 충분하지 못했다.
반면 자연어를 이용한 학습은 훨씬 더 다양한 시각적 개념을 표현할 수 있는 잠재력을 가진다. Weak label을 사용하는 대신 자연어 캡션을 직접 지도 신호로 사용하는 대규모 학습을 진행하는 것이다. 기존 연구들이 수십만 장 단위의 이미지로 제한된 학습을 진행한 것과 달리 본 연구에서는 4억개의 (image, text) 쌍으로 구성된 새로운 데이터셋을 만들어 Natural Language Supervision at Scale(대규모 자연어 기반 사전학습)을 수행한다.
이 방법을 통해 이 논문에서는 CLIP (Contrastive Language–Image Pre-training)을 제안한다. 이 모델은 이미지와 텍스트 쌍을 동시에 인코딩하고, 서로 대응되는 쌍의 표현 간 거리를 최소화(contrastive objective)함으로써 학습된다. 그 결과, CLIP은 기존의 weakly supervised 모델보다 훨씬 강력한 일반화 성능을 보였으며, zero-shot 상황에서도 supervised baseline과 유사한 수준의 성능을 달성했다.
Approach
Natural Language Supervision
CLIP에서 사용하는 방법론의 핵심은 자연어를 training signal로 이해하고, 이를 통해 image perception을 학습하는 것이다. 이를 Natural Language Supervision이라고 한다. 이런 방식은 labeled data가 필요 없기 때문에 scalability가 좋다.
Does not require annotations to be in a classic machine learning compatible format.
Can learn from the supervision contained in the vast amount of text.또 하나의 특징은 단순히 이미지에 대한 representation을 학습하는 것을 넘어, 그 representation을 자연어에 연결해 few-shot transfer가 가능하게 만든다는 것이다. 이렇게 연결하는 것을 allignment of representation이라고 한다. 이미지와 텍스트의 embeddings를 같은 벡터 공간에 나타내는 것이다.
Creating a Sufficiently Large Dataset
CLIP과 유사한 기존 연구들이 사용한 데이터셋 중 크기각 가장 큰 것은 1500만장(ImageNet과 유사) 정도의 이미지를 가진다. 다른 Vision 모델 아키텍처들은 최대 35억개의 인스타그램 사진에 대해 훈련되는 것을 고려하면 너무 작은 크기의 데이터셋을 이용해왔다.
Natural Language Supervision의 장점이 여기서 나타난다. 인터넷에 존재하는 방대한 양의 (이미지, 텍스트) 쌍 데이터를 그대로 사용할 수 있는 것이다. CLIP은 4억개의 쌍을 수집해 구성된 데이터셋을 학습한다. 가능한 넓은 범위의 시각적 특징들을 학습하기 위해 최대한 여러가지 query를 이용해 class balancing을 이룬다. 이 데이터셋을 WIT (WebImageText)라고 부른다.
이렇게 굉장히 큰 데이터셋을 학습했기 때문에 overfitting은 큰 문제가 되지 않는다. 단순히 데이터셋의 크기가 큰 것 덕분은 아니고, 웹 전체에서 수많은 도메인의 데이터를 수집한 것이기 때문에 데이터 규모가 크면서 동시에 분포까지 넓은 web-scale multimodal data이기 때문이다. Augmentation도 복잡하지 않고 단순히 random center crop 정도만 적용한다.
Selecting an Efficient Pre-Training Method
이전의 모델들은 ImageNet 데이터셋의 1000개 클래스만을 학습하는 데에도 몇십 개의 GPU로 수 년의 학습이 필요했다. Natural Language Supervision을 추출하는 데에는 단순 라벨을 이용하는 것보다 더 많은 자원이 들기 때문에 training efficiency를 최대화하는 것이 핵심이다.
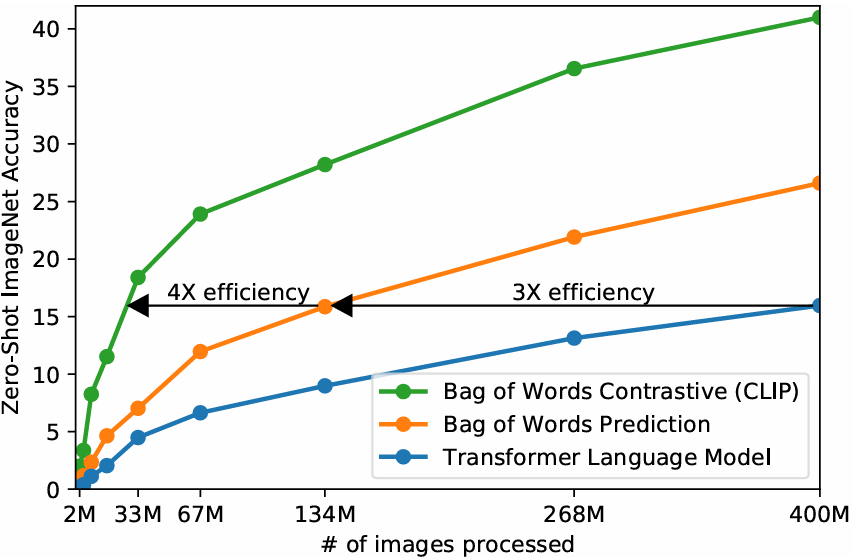
앞선 연구에서 predictive objective를 사용하는 것보다 contrastive objective를 사용하는 것이 이미지와 텍스트의 representation을 더 잘 학습한다는 것이 밝혀졌다. 이미지와 함께 오는 정확한 단어를 예측하는 것은 텍스트의 매우 큰 표현 다양성으로 인해 어렵다.

위와 같은 하나의 이미지에서도 아래와 같은 여러 개의 텍스트가 함께 올 수 있다.
- A cat sitting on a sofa
- A sofa with a cat on top
- A relaxed kitten indoors이런 이유로 텍스트 자체를 정확히 예측하는 predictive objective는 매우 비효율적인 것이다. 이를 개선하기 위해 이미지와 텍스트의 representation을 align 시키는 것을 학습하는 contrastive objective가 주어진다.
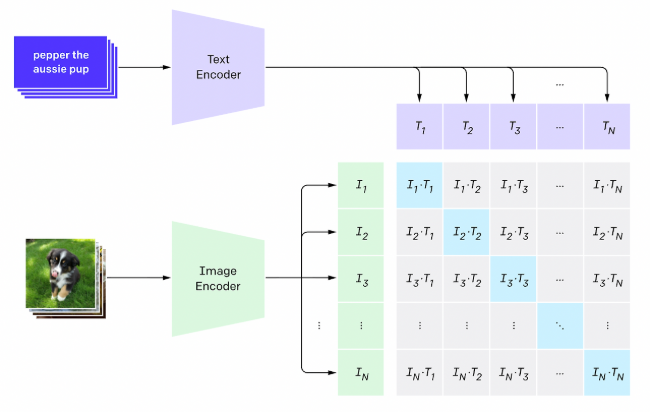
Batch 내의 이미지-텍스트 쌍 중 한 쌍을 positive pair로, 다른 쌍을 모두 negative pair로 간주한다. Positive pair 간의 cosine similarity를 증가시키고, negative pair의 것은 감소시키는 방향으로 학습하면 유사한 이미지와 텍스트 쌍이 embedding space에서 가깝게 매핑된다.
Pseudocode로 나타내면 다음과 같다.
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2각 인코더를 통해 얻어진 embedding vector는 linear projection을 통해 embedding space에 매핑된다.
Choosing and Scaling a Model
Image Encoder로는 ResNet-50 또는 ViT가 사용된다. 둘 다 아주 약간의 수정 외에는 기존 모델을 거의 그대로 사용한다. Text Encoder로는 transformer를 사용했는데, 8개의 헤드와 12개의 layer를 사용하였고 max sequence length는 76으로 제한했다.
CLIP는 text encoder의 용량에 덜 민감하기 때문에, RseNet의 계산된 너비 증가에 비례하도록 모델의 너비를 스케일링할 뿐 모델의 깊이는 스케일링하지 않는다.