Introduction
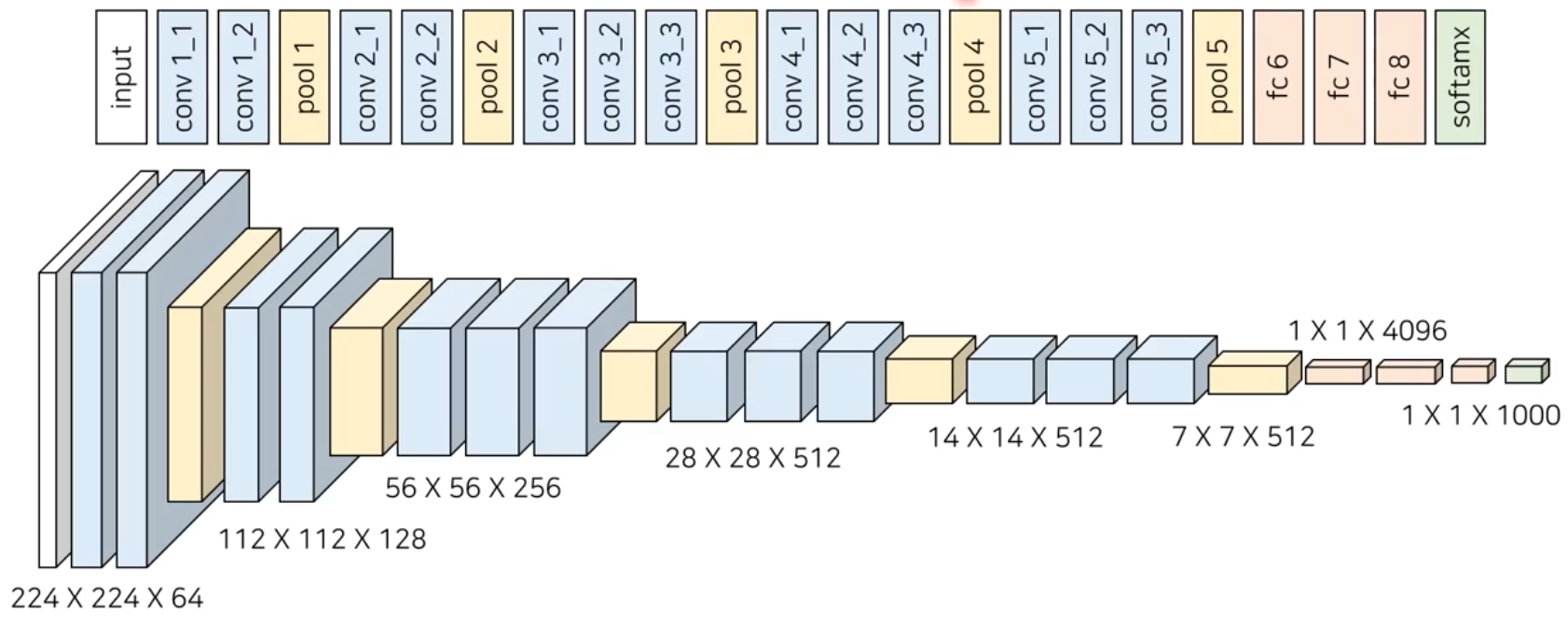
깊은 층을 가지는 CNN 구조들은 이미지 분류에서 좋은 성능을 보였다. 위 사진에 보이는 것은 이전까지 ImageNet 분류 대회에서 좋은 성적을 거뒀던 VGG-net으로, 3x3이라는 작은 크기의 커널과 많은 층을 사용해 좋은 성능을 냈다. 층의 갯수가 많아진다는 것은 사용할 수 있는 정보의 추상화 정도가 다양하다는 것이고, 이것이 높은 성능으로 이어질 수 있던 이유다. 하지만 무조건 층의 갯수가 많은 것이 좋은 것일까?
Convergence Problem
층을 깊게 쌓을 때 가장 큰 장애물은 Vanishing / Exploding Gradients다. 깊은 신경망에서는 출력층에서 계산된 loss gradient가 역전파를 통해 여러 층을 거치며 전달된다. 이때 각 층의 weight와 activation의 미분값이 연속으로 곱해지기 때문에, 이 값들이 1보다 작으면 gradient가 층을 거칠수록 기하급수적으로 작아지고(vanishing), 1보다 크면 기하급수적으로 커진다(exploding). 이렇게 너무 작은/큰 gradient가 누적되면 파라미터 업데이트가 거의 되지 않거나, 반대로 발산하여 학습이 불안정해진다.
Degradation Problem
Batch Normalization, Weight Initialization, ReLU, SGD 등의 방법을 통해 Convergence Problem을 어느 정도 완화할 수 있다. 하지만 다른 문제가 발견되는데, 네트워크가 깊어질수록 성능이 빠르게 포화되고 이후에 급감하는 현상이다.
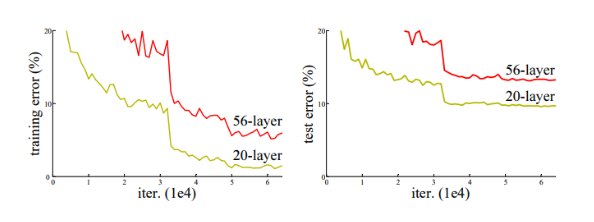
이 현상은 과적합으로 인한 것이 아니라 위 그래프에서 보이는 것처럼 깊은 네트워크로 인해 training error가 증가한 것이 원인이다. 오히려 깊은 층을 가진 모델이 학습을 잘 못 수행하는 것이다. 이 논문에서는 degradation problem을 해결하기 위해 deep residual network을 소개한다.
Deep Residual Learning
Residual Learning
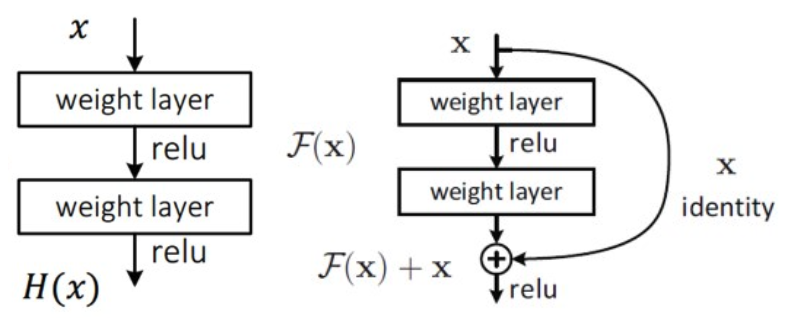
Deep Residual Network는 Residual Block이라는 구조를 이용해 네트워크의 최적화 난이도를 낮춘다. 기존의 네트워크에서 학습하려 했던 목적 함수를 라고 하자. 논문에서는 이것을 직접 학습하는 것보다, 학습하기 쉬운 형태가 존재한다고 주장한다. 그 형태는 로, 이전의 입력이 몇 개의 층을 건너뛰어 출력에 더해지는 양상이다. 이것은 에 비해 identity mapping에 가깝다. 또한 이전 층의 출력인 를 그대로 가져올 수 있기 때문에 모든 weight layer의 가중치에 대한 학습을 해야 했던 이전과 달리 학습해야 하는 정보의 양이 줄었다. 이로 인해 학습이 쉬워진다는 것이다.
Identity Mapping by Shortcuts

이전 레이어의 출력값이 skip connection이라는 통로를 통해 여러 레이어를 거쳐 이후 레이어의 출력 값에 더해지는 것이다. 여러 레이어를 거친 출력을 로 표현하는데, 여러 레이어의 가중치 행렬과 그 사이의 활성화 함수가 곱해지는 형태를 의미한다. 이후에는 이전 레이어의 출력을 더해주는 shortcut에 대한 식이 등장한다. 와 의 차원이 같다면 identity mapping의 형식으로 더해주면 되고, 차원이 다르다면 를 이용해 projection을 거친 후 더해주면 된다.
Network Architecture
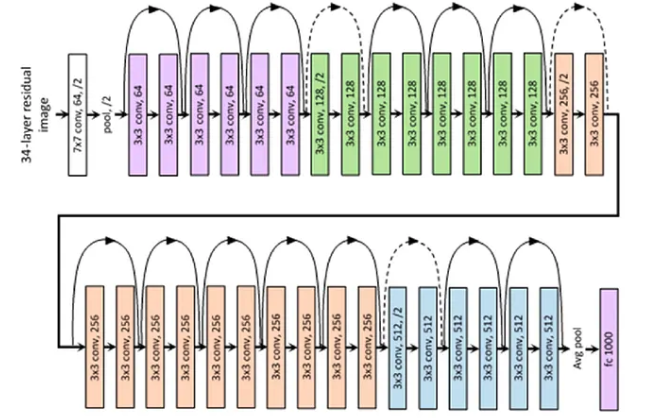
34개의 weight layer로 이루어진 ResNet-34의 구조다. 7x7 conv, 64, /2 는 커널 크기, 필터 갯수, stride를 나타낸다. 이를 통해 입력 사이즈가 어떻게 변하는지 알 수 있다.