문제상황
모든 서비스를 하나의 EC2 인스턴스에 컨테이너로 올려서 운영하다 보니 메모리가 부족해 OpenSearch-dashboard를 제거하고, Airflow 대신 Prefect를 선택할 수밖에 없었습니다. FastAPI 컨테이너에 모델 3개를 한꺼번에 올리자 또 다시 메모리 문제가 발생했고, 결국 EC2를 t3.large로 업그레이드하고 스토리지 용량도 늘리는 수직 확장 방식으로 대응했습니다. (만약, 당신도 제거했다면, OpenSearch-dashboard는 다시 띄우는 것을 추천드립니다 인덱스랑 쿼리를 보기가 너무 힘들어져요.. 어떻게 아냐구요? 저도 알고싶지 않았습니다 🥲)
그럼 어떻게 해야할까?
하지만 이렇게 서버 사양을 키우는 방식에는 분명한 한계가 있었습니다. 한 서버가 커질수록 비용이 급격히 올라가고, 장애가 나면 올려둔 모든 서비스가 한꺼번에 영향을 받게 됩니다. 그래서 각 서비스를 역할별로 나누어 EC2 인스턴스에 분리 배포하는 설계를 고민하게 되었습니다. Scale Out(수평 확장)을 가능하게 만드는 준비 단계라고 생각했습니다. 서비스를 역할별로 분리해두면, 나중에 특정 서비스의 트래픽이 몰릴 때 그 서비스만 독립적으로 여러 인스턴스로 확장해 분산처리를 할 수 있기 때문입니다.
- Airflow-webserver, Airflow-scheduler ...
- Mlflow-server
- OpenSearch-node, OpenSearch-dashboard
- FastAPI
모델별로 컨테이너 설계하기
현재는 빠른 개발을 위해 모델별로 컨테이너를 따로 나누지않았지만, FastAPI 모델 서버의 경우, 모델이 커지거나 요청량이 많아질 때는 모델별로 컨테이너를 따로 만들어 배포하는 것이 좋다고 생각합니다. 첫번째로, 컨테이너 하나가 하나의 모델만 메모리에 올려 훨씬 가볍고 효울적이기 때문입니다. 두번째로, 모델 A 컨테이너가 죽어도 모델 B, C는 정상적으로 작동이 가능합니다. 세번째로, 모델별로 요청량이 다를 때, 특정 모델 컨테이너만 여러 개 띄워서 처리량을 늘릴 수 있습니다.
Load Balancing 왜 필요해?
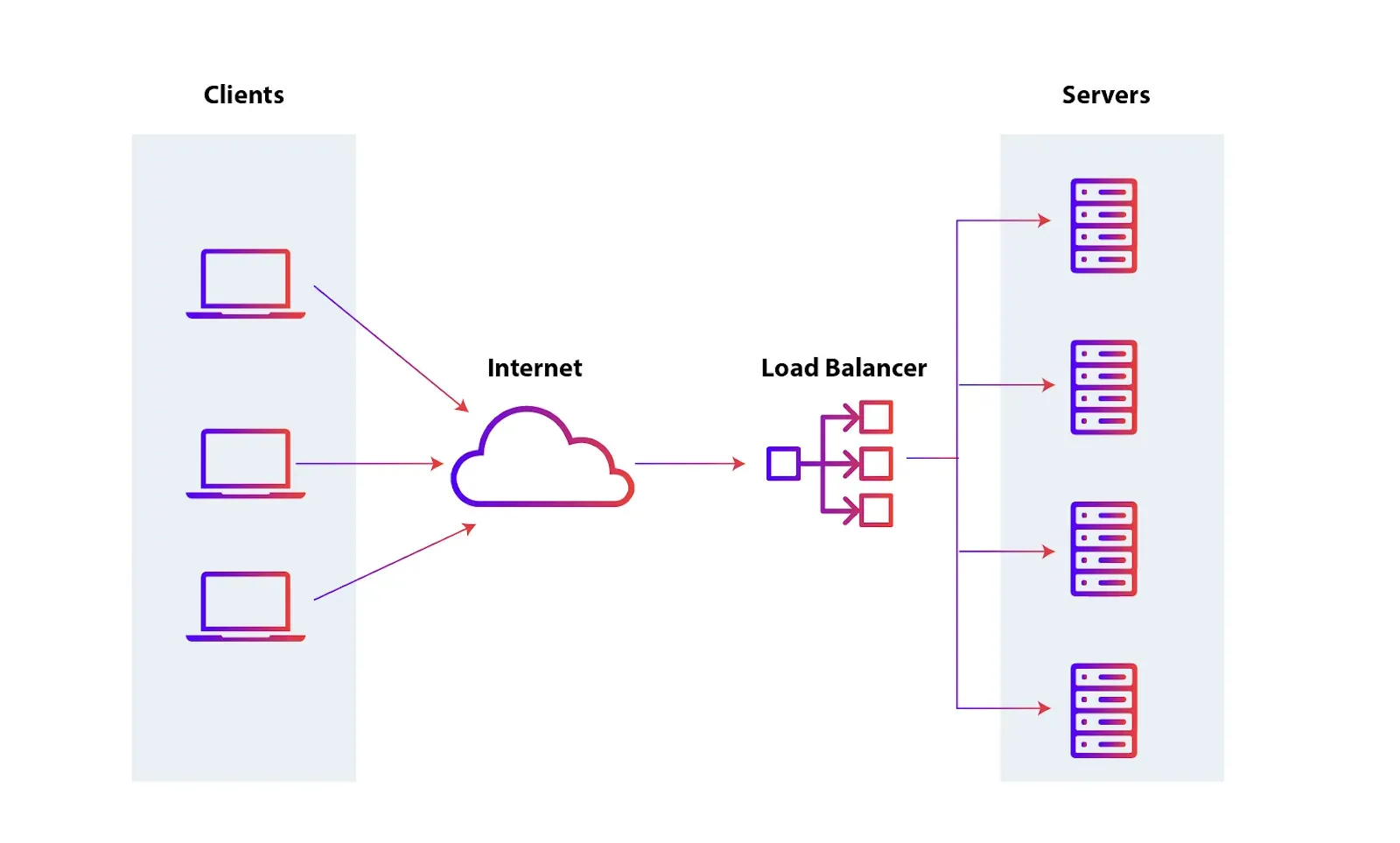
컨테이너를 여러 개 나누면 어디로 요청을 보내야 할 지 결정하는 것이 필요합니다. 이때, Load Balancer가 자동으로 요청을 여러 컨테이너로 분산해 주어 트래픽을 고르게 나누고 서버의 과부하를 방지할 수 있습니다. 또한 특정 컨테이너가 장애가 나더라도 다른 컨테이너로 요청을 자동으로 전달해 서비스의 가용성을 높여 줍니다.
Next Step

Ref.
로드 밸런싱이란 무엇인가요? - 로드 밸런싱 알고리즘 설명 - AWS
Load Balancer | Types of Load Balancers | Benefits of Load balancer