주어진 서비스 기능들을 검토한 결과, 온라인 추론이 필요한 요구사항이 없다고 판단하여, 오프라인 추론 방식으로 아키텍처를 구성했습니다. 추천 시스템을 개발하면서 가장 먼저 고민했던 부분은 모델 배포와 재학습 자동화였습니다. 이 글에서는 모델의 배포 및 재학습 파이프라인부터 시작해, 운영 환경에서의 전체 아키텍처 구성, 그리고 OpenSearch를 선택하게 된 이유까지 단계별로 설명드리겠습니다.
모델 배포 자동화 프로세스
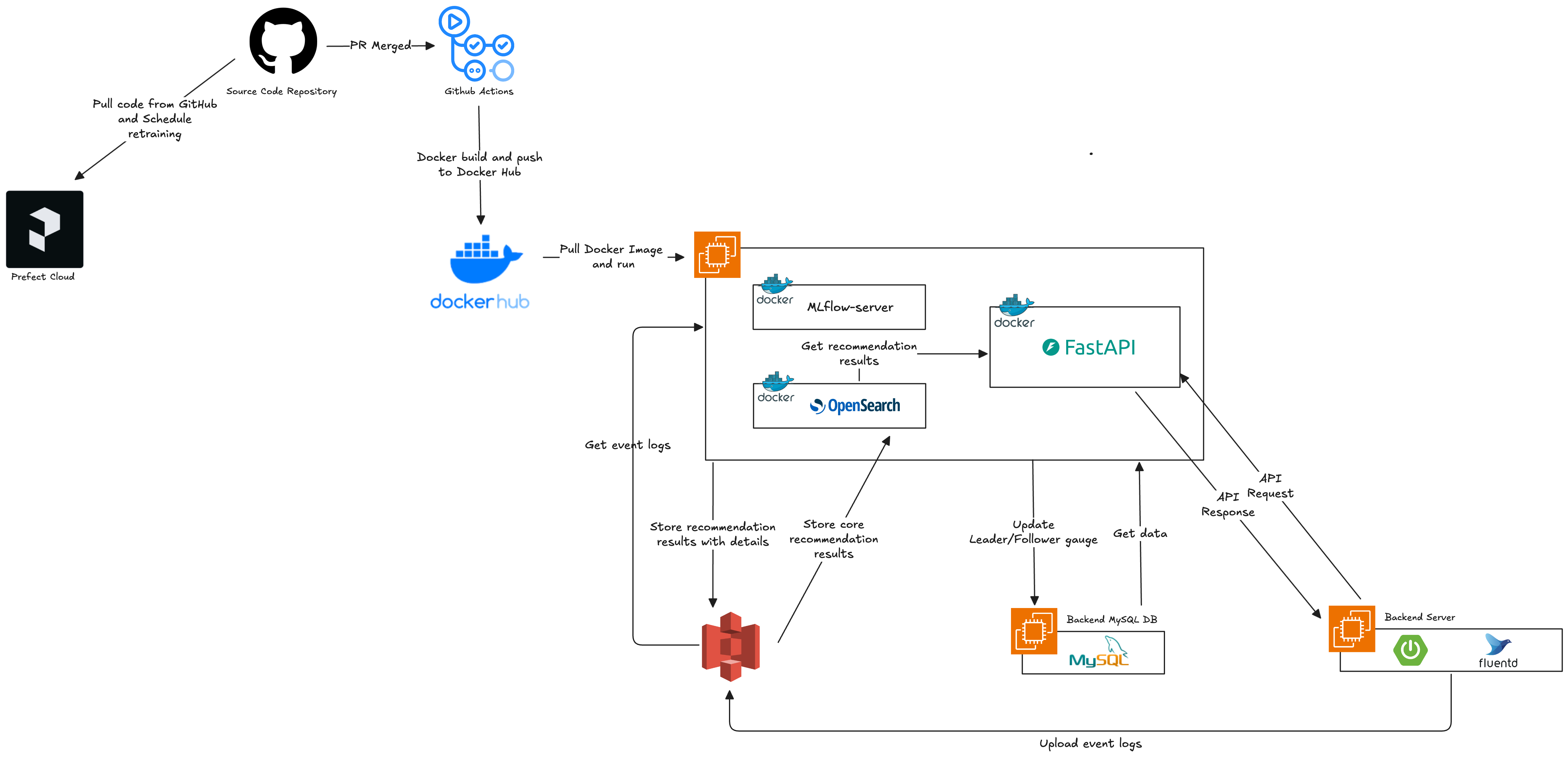
저는 GitHub의 main 브랜치에 코드가 머지되면 GitHub Actions가 자동으로 실행되도록 구성했습니다. GitHub Actions는 도커 이미지를 빌드한 뒤, Docker Hub에 푸시하도록 설정했습니다. 이렇게 생성된 이미지는 EC2 서버에서 Docker Hub에서 Pull 받아 실행되며, 이를 통해 최신 코드가 자동으로 배포되도록 설계했습니다.
재학습 자동화 파이프라인
모델 재학습은 Prefect Cloud를 활용하여 자동화했습니다. Prefect는 GitHub의 main 브랜치 코드를 주기적으로 가져와 학습 파이프라인을 스케줄에 따라 실행할 수 있도록 도와주는 오케스트레이션 도구입니다. 따로 인프라 구축을 하지 않아도 Prefect Cloud에서 자동으로 스케줄을 실행해줍니다.
초기에는 Airflow도 고려했으나, 메모리 사용량이 과도해 서버 자원이 부족한 환경에서 사용하기에는 어려움이 있었습니다. 이에 따라 더 가벼운 Prefect를 선택하게 되었습니다.
재학습 파이프라인은 다음과 같은 단계로 구성했습니다.
S3에서 로그 데이터를 수집하고
MySQL에서 메타데이터를 함께 조회한 뒤
로그와 메타데이터를 결합하여 전처리를 수행하고
피처 엔지니어링을 통해 학습 데이터를 생성하고
모델을 학습한 후
사용자별 추천 결과를 S3에 저장했습니다.
최종적으로는 이 추천 결과를 OpenSearch에 업로드하여, API 요청 시 빠르게 조회할 수 있도록 구성했습니다.
운영 환경 아키텍처
모델을 운영하는 EC2 인스턴스에는 FastAPI, OpenSearch, MLflow Server 컨테이너가 구동되도록 구성했습니다. 사용자의 이벤트 로그는 Backend Server에서 수집되며, Fluentd가 이를 모아서 S3에 업로드하도록 구성했습니다. 이 이벤트 로그는 재학습 시 학습 데이터로 활용되었습니다.
모델 학습이 완료되면, 사용자별 추천 결과를 S3에 저장하고, 핵심적인 결과만 OpenSearch에 별도로 저장했습니다. FastAPI에서 백엔드 서버가 ML 서버의 API를 호출하면, ML 서버는 OpenSearch에서 사용자별 추천 결과를 조회하여 응답하도록 구성했습니다.
추천 결과 저장 구조

S3는 장기 보관과 백업용으로는 훌륭하지만, 읽기 속도가 상대적으로 느려서 API가 바로 접근하기에는 부적합합니다. 그래서 S3는 추천 점수나 상세 정보 등 다양한 데이터를 포함한 전체 추천 결과 원본을 저장하는 저장소로 사용하기로 했습니다. 반면에 OpenSearch는 검색 속도가 빠르기 때문에, 사용자 API 요청이 들어왔을 때 필요한 핵심 추천 결과만 빠르게 제공할 수 있도록 활용했습니다.
왜 OpenSearch를 선택했는가?
초기에는 MongoDB를 고려했습니다. MongoDB는 JSON 형태로 데이터를 저장할 수 있고, 특정 ID 기반 조회 속도가 빠르다는 장점이 있었습니다. 그러나 사용자 발화를 벡터화해 관련 상품을 검색하거나 추천하는 기능이 추가되면서, 벡터 검색이 가능한 Vector DB가 필요해졌습니다.
내부 Vector DB도 고려했지만, 메모리 기반 구조로 인해 서버가 재시작되면 인덱스가 초기화되고, 다시 로딩해야 하는 문제가 있었습니다. MongoDB와 외부 Vector DB를 조합해서 사용하는 방안도 고민했지만, 외부 VectorDB와 MongoDB 두 개의 DB를 사용하는 것보다 OpenSearch 하나만 사용하는 것이 더 나은 선택이라고 판단했습니다.
OpenSearch는 다음과 같은 이유로 선택하게 되었습니다.
벡터 검색이 가능하여 외부 Vector DB로 활용 가능했습니다.
JSON 형식의 다양한 메타데이터 저장이 가능했습니다.
복합 필터링 기능이 강력하여, 향후 추천 고도화에 적합했습니다.
복합 필터링은, 예를 들어, 사용자가 ‘소형 세탁기’를 자주 검색했다면, 추천 시 ‘소형’이라는 필터를 적용하고, 가격대도 최근 본 제품과 유사한 범위로 제한할 수 있습니다.