An
EntityManagerinstance is associated with apersistence context. Apersistence contextis a set of entity instances in which for any persistent entity identity there is a unique entity instance. Within thepersistence context, the entity instances and their lifecycle are managed. TheEntityManagerAPI is used to create and remove persistent entity instances, to find entities by their primary key, and to query over entities.
Persistence Context(영속성 컨텍스트)는 모든 Entity ID에 대해 Entity 객체가 존재한다. Persistence Context 내부에는 Entity 객체와 생명주기가 관리되고 Entity Manager API는 그러한 Persistence Context 객체를 생성 및 제거를 하고, PK를 이용해 Entity를 찾고 쿼리하는데 사용된다.
해당 포스트를 전부 읽으면 (또는 김영한의 "자바 ORM 표준 JPA 프로그래밍"을 읽는다면) 공식 문서의 해당 글귀를 완벽히 이해할 수 있다.
들어가기 앞서
이전 포스트에서 우리는 JPA가 SQL 의존적인 개발에서 자유롭게 해준다는 것을 배웠다.
하지만 JPA가 어떤 구조로 되어있길래 이 모든 것이 가능한 걸까? 또 그놈의 영속성 컨텍스트가 뭐길래 중요하다고 말하는 걸까?
사실 영속성 컨텍스트는 JPA의 핵심이고 대부분의 기능은 JPA의 영속성 컨텍스트에서 일어나기 때문에 확실히 알아두면 추후에 나올 프록시, 트랜잭션에도 영속성 개념은 계속해서 쓰일 것이다.
그리고 다양한 연령대의 개발자들과 대화를 하다 보면 누구는 Persistence Manager, 누구는 영속성 매니저, 누구는 Entity Context이라고 부를 정도로 바리에이션이 다양하다 보니 개념이 잘 안 잡힌 학부생 혹은 주니어 개발자라면 헷갈리기 마련이다.
이번 기회에 확실히 알아듣고 개떡같이 말해도 찰떡같이 알아듣는 개발자가 되자.
Entity Manager Factory (엔티티 매니저 팩토리)
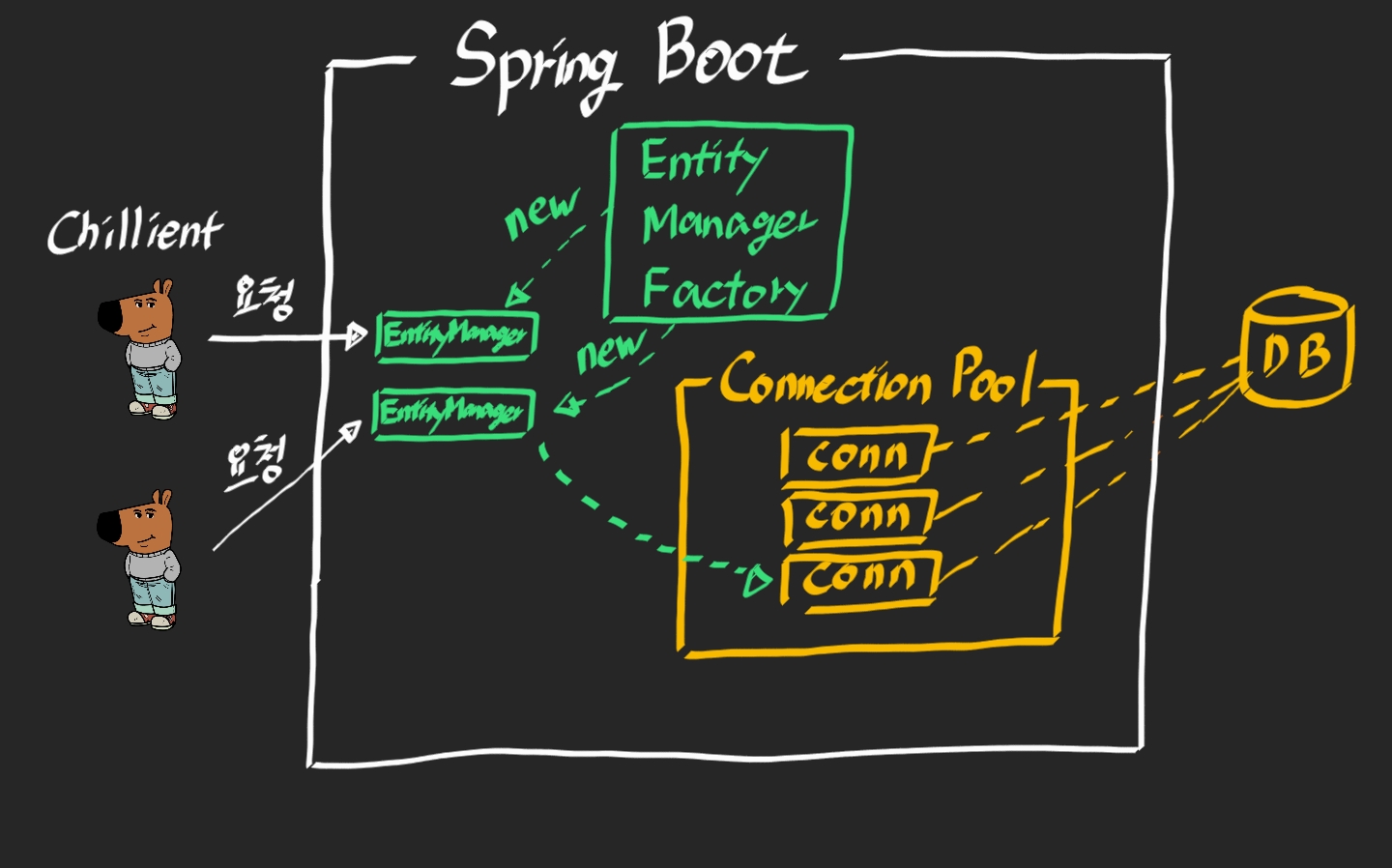
Entity Manager Factory는 직관적이게 Entity Manager를 만들어준다.
초기 생성 비용이 많이 들기때문에 프로그램이 동작하면서 한 개만 만들어져서 공유되도록 설계되어 있고 Entity Manager는 생성 비용이 거의 들지 않는다.
Entity Manager Factory는 여러 스레드가 동시 접근해도 동시성 문제가 발생하지 않지만
Entity Manager는 동시성 문제가 발생해서 공유하면 안된다.
Persistence Context (영속성 컨텍스트)
영속성 컨텍스트, 영구적인, Entity를 영구 저장하는 환경
아직까지도 그렇게 대단한 개념인지는 와닫지 않는다.
Entity LifeCycle (엔티티 생명주기)
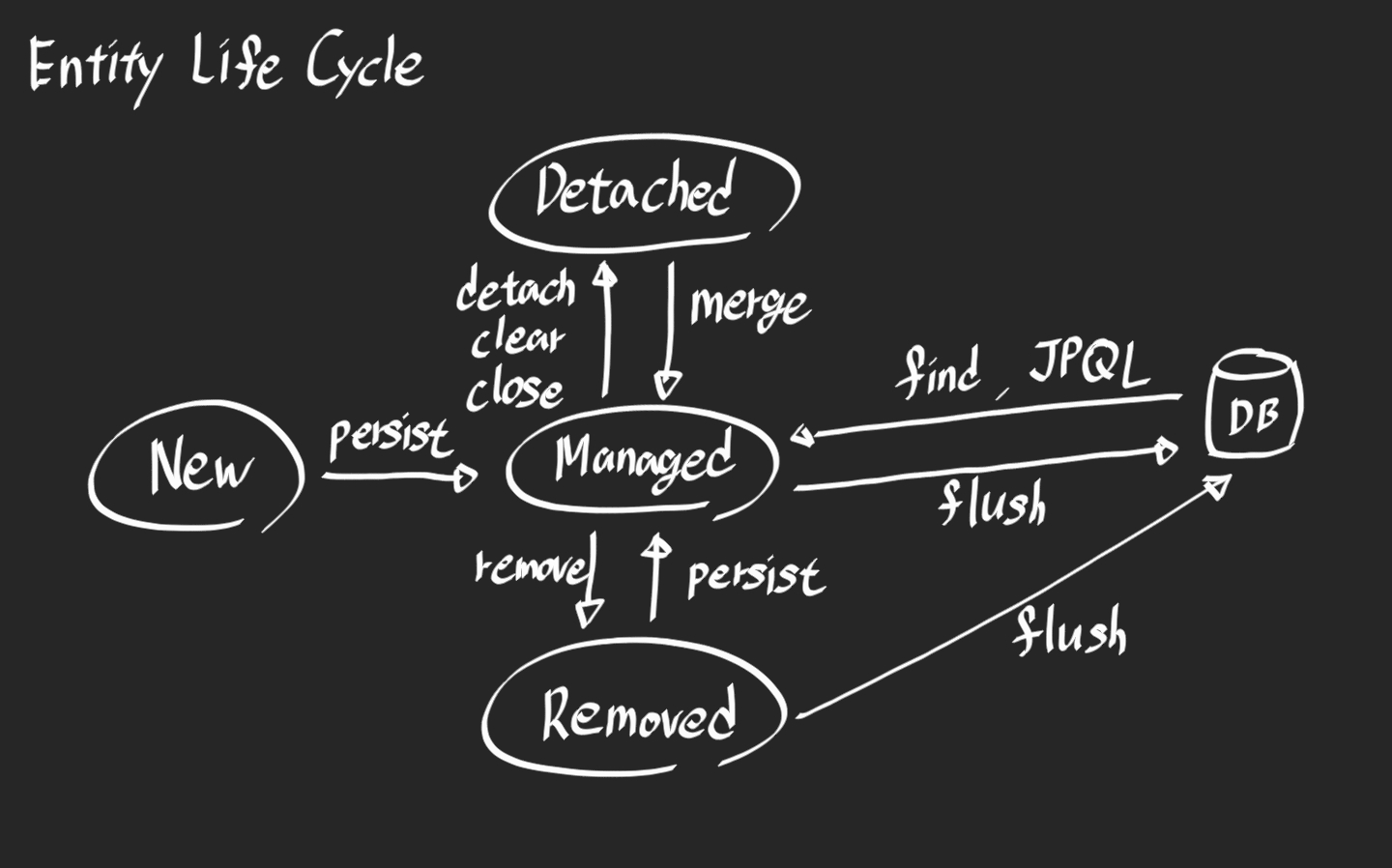
비영속(new) : Persistence Context와 전혀 관계 없음
영속(managed) : Persistence Context 에 저장된 상태, 관리하는 상태
준영속(detached) : Persistence Context에 저장되었다가 분리된 상태
삭제(removed) : 삭제된 상태
사실 이런 부분에서 JPA를 확실히 익히려고 하는건데,
만약 Spring Data JPA 만 사용했다면, persist(), EntityManager em, merge() 등등의 함수는 생소할 것이다.
public interface MemberRepository extends JpaRepository<Member, Long> {}이런 식으로 상속받으면 EntityManager를 직접 주입 받고 persist() 같은 과정을 겪어야 하지만 Spring에서 모두 추상화 했기 때문에 순수 JPA 를 접하지 않은 사람은 EntityManager가 뭔지 Persistence Context가 뭔지 이해하기 어려울 것이다.
비영속
Member member = new Member();
member.setId("member");
member.setUsername ("ChillGuy");
가장 먼저 간단한 비영속부터 그림으로 보자.
단순하게 Member 객체를 생성하고 필드값을 지정해준 것 뿐이다.
당연히 Entity Manager는 Member객체의 존재 여부 조차 모르고 있다.
영속(Managed)
Member member = new Member();
member.setId("member");
member.setUsername ("ChillGuy");
//EntityManager em;
em.persist(member);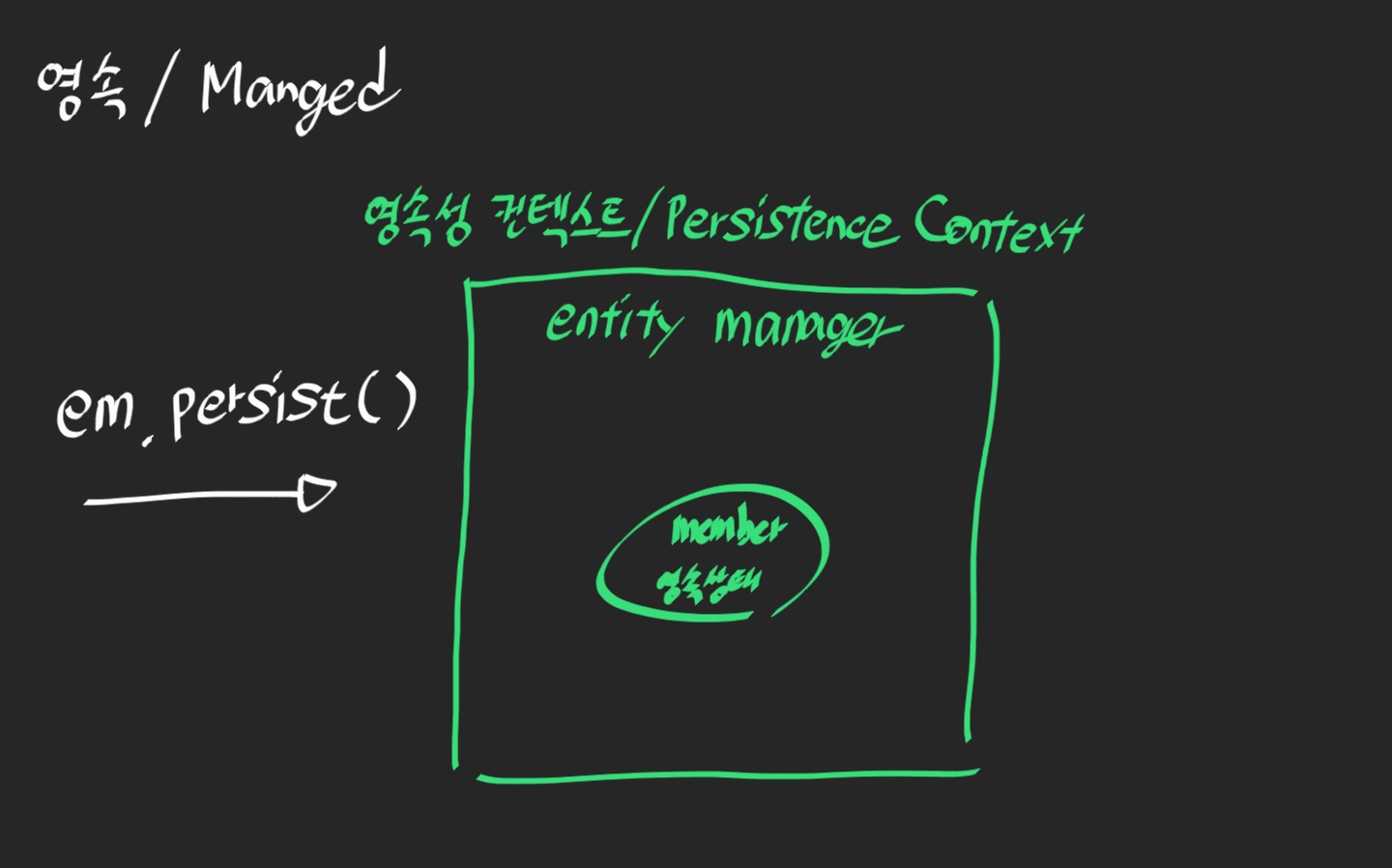
이제 em.persist()를 실행하면 EntityManager 객체가 member 객체를 관리하게 되면서 이를
영속 상태 라고 한다.
다음으로 준영속과 삭제를 소개하려고 했지만 Persistence Context의 내부 구조를 자세히 알면 더 쉽게 이해할 수 있기 때문에 뒤에서 설명한다.
Persistence Context 특징
1차 캐시
동일성 보장
트랜잭션을 지원하는 쓰기 지연
변경 감지 (Dirty Read)
지연 로딩 (LAZY)
언뜻 보기에도 중요한 개념들이 무더기로 등장했다. 이 내용을 Entity Manager 내부 구조를 살펴보며 이해해보자.
1차 캐시
개념 보단 그림으로 보는 것이 한번에 와닫는다.
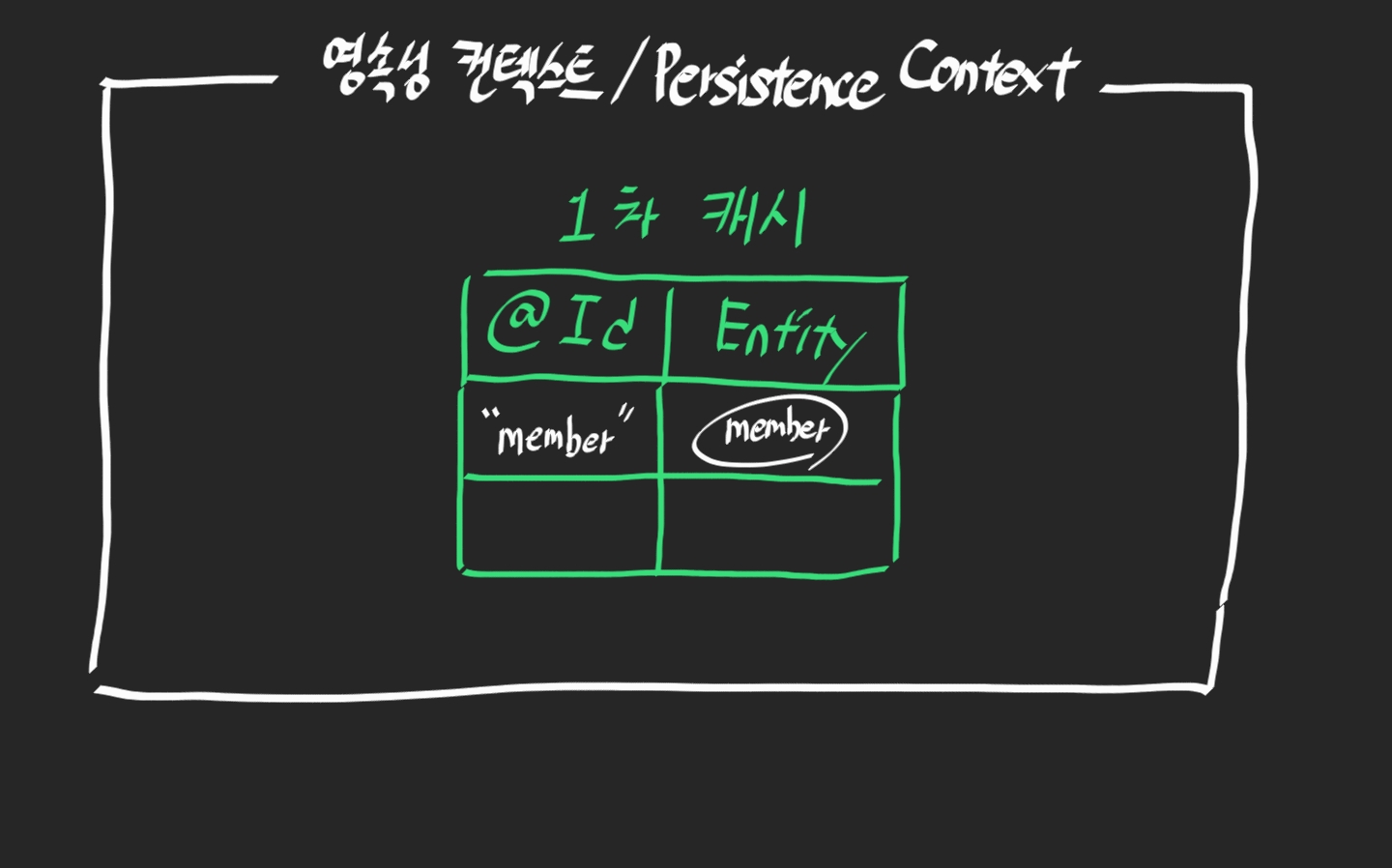
보잘것 없이 생긴 이놈이 1차 캐시 이다.
영속 상태의 모든 Entity는 1차 캐시라는 Map에 저장된다.
@Id 값과 나머지 Entity 객체이다.
직전의 그림에서 em.persist()를 실행하면 Persistence Context가 영속 상태인 Entity를 관리하게 되고 바로 어딘가로 보내버리는 것이 아닌 1차 캐시에 저장한다.
보내라면 보낼 것이지 왜 안보내는 거야? 다음과 같은 이점이 있기 때문에 그러지 않는다.
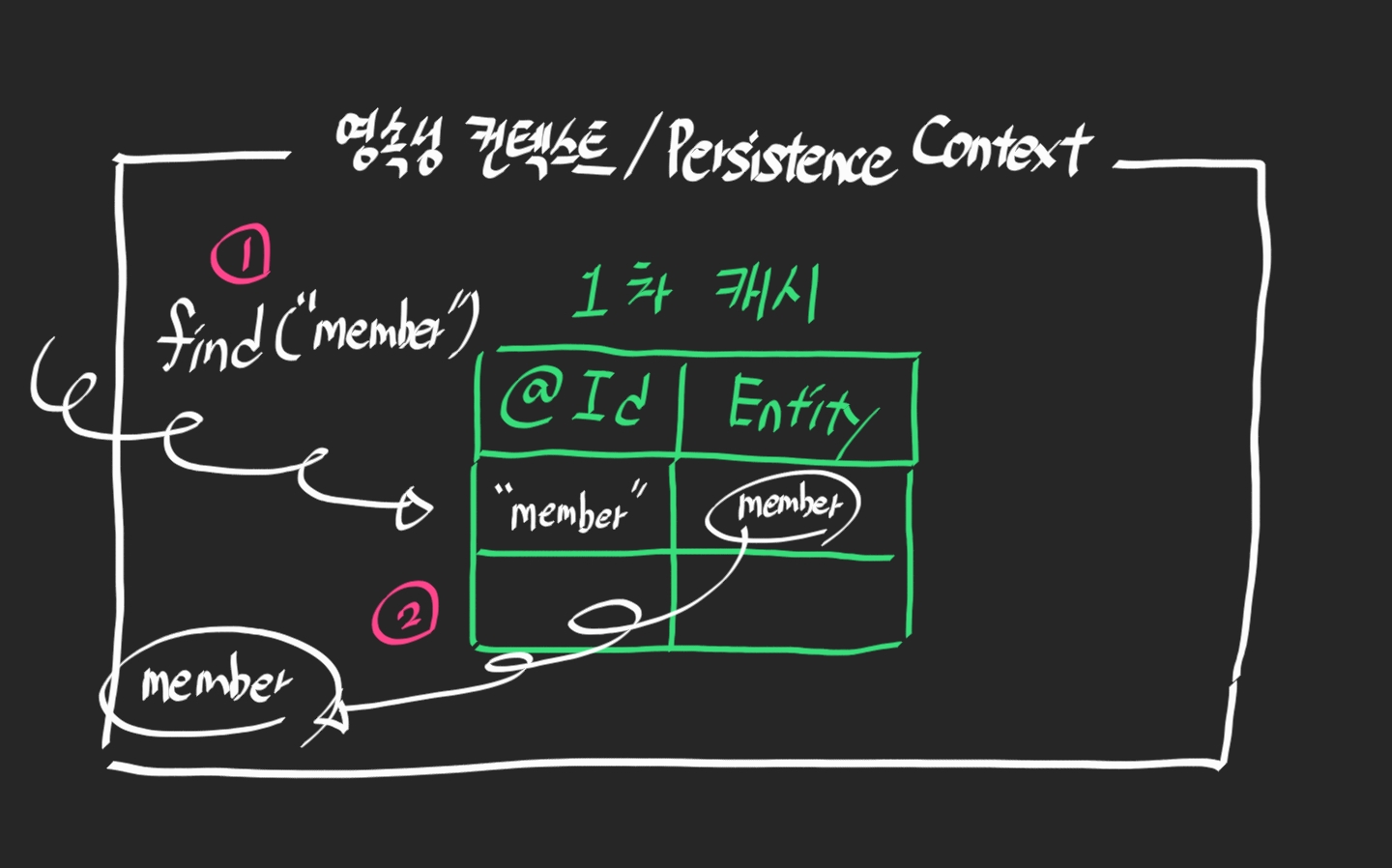
우리가 저장이 잘 됐나? 하고 find(member)를 하지만 사실 데이터베이스까지 가지도 않고 1차 캐시에 있는 내용을 가져온다. 그로 인해 속도 측면이나 메모리 사용면에서 효율이 좋다.
만약에 1차 캐시에 존재하지 않는 데이터를 조회하려고 하면?
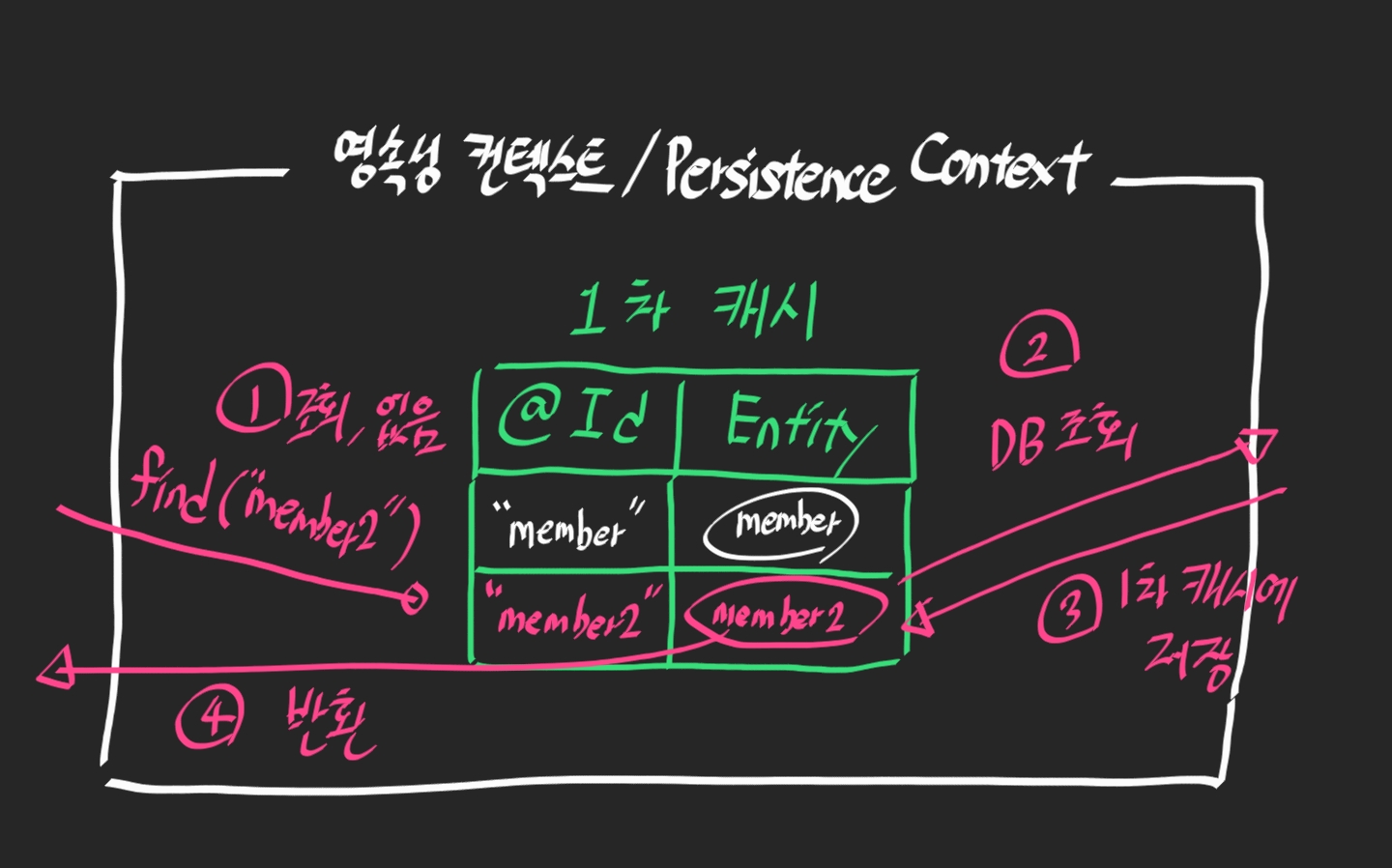
그제서야 데이터베이스에서 조회 후, 1차 캐시에 저장한 다음 반환해준다.
동일성
이처럼 1차 캐시에 저장할 내용, 조회한 내용들을 담아두기 때문에
Member a = em.find(Member. class, "memberl");
Member b = em.find(Member.class, "memberl");
a==b // 같다JDBC 에서는 동일성 비교에서 false이지만 JPA에서는 동일한 객체임을 보장한다.
이와 관련하여 REPEATABLE READ(반복 가능한 읽기) 등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 Persistence Context 가 제공할 수 있다.
쓰기 지연
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
//엔티티 매니저는 데이터 변경 시 트랜잭션을 시작해야 한다.
transaction.begin (); //트랜잭션 시작
em.persist(memberA);
em.persist(memberB);
transaction.commit(); // 커밋과 동시에 쿼리 전송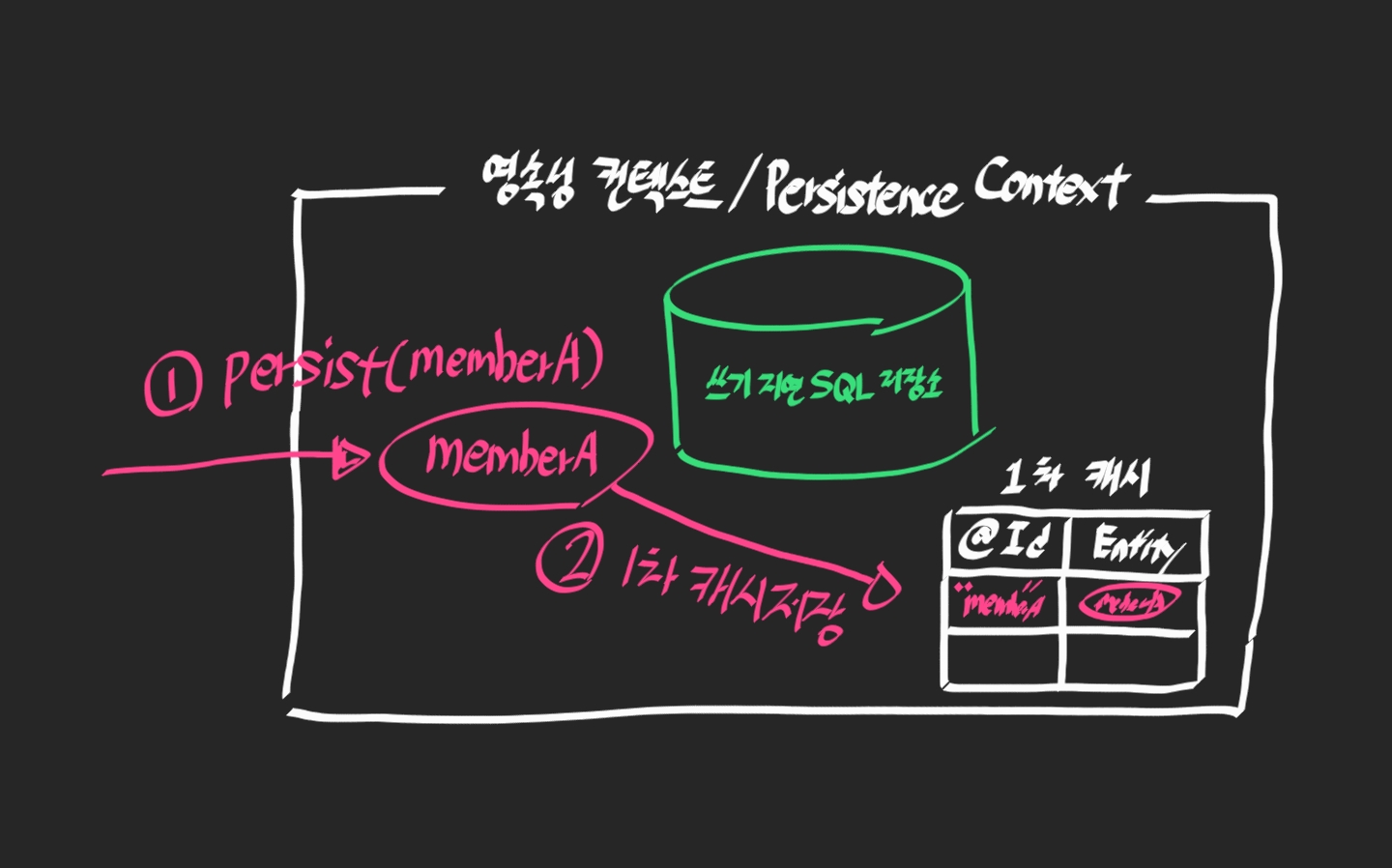
직전까지 배운 내용을 토대로 1차 캐시까지 Entity가 저장이 된다.
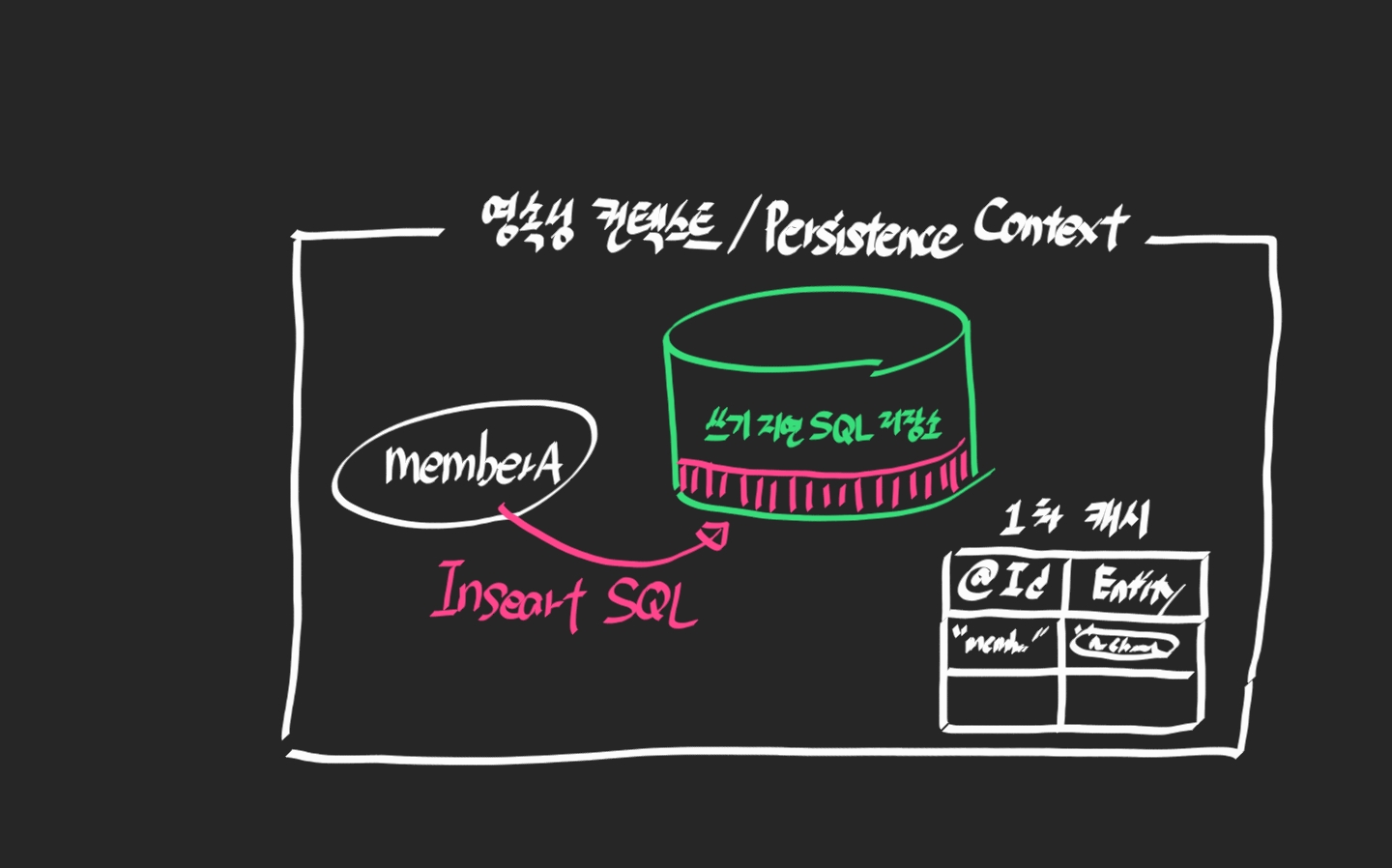
이후 추가된 동작이 쓰기 지연 SQL 저장소에 INSERT SQL을 저장한다.
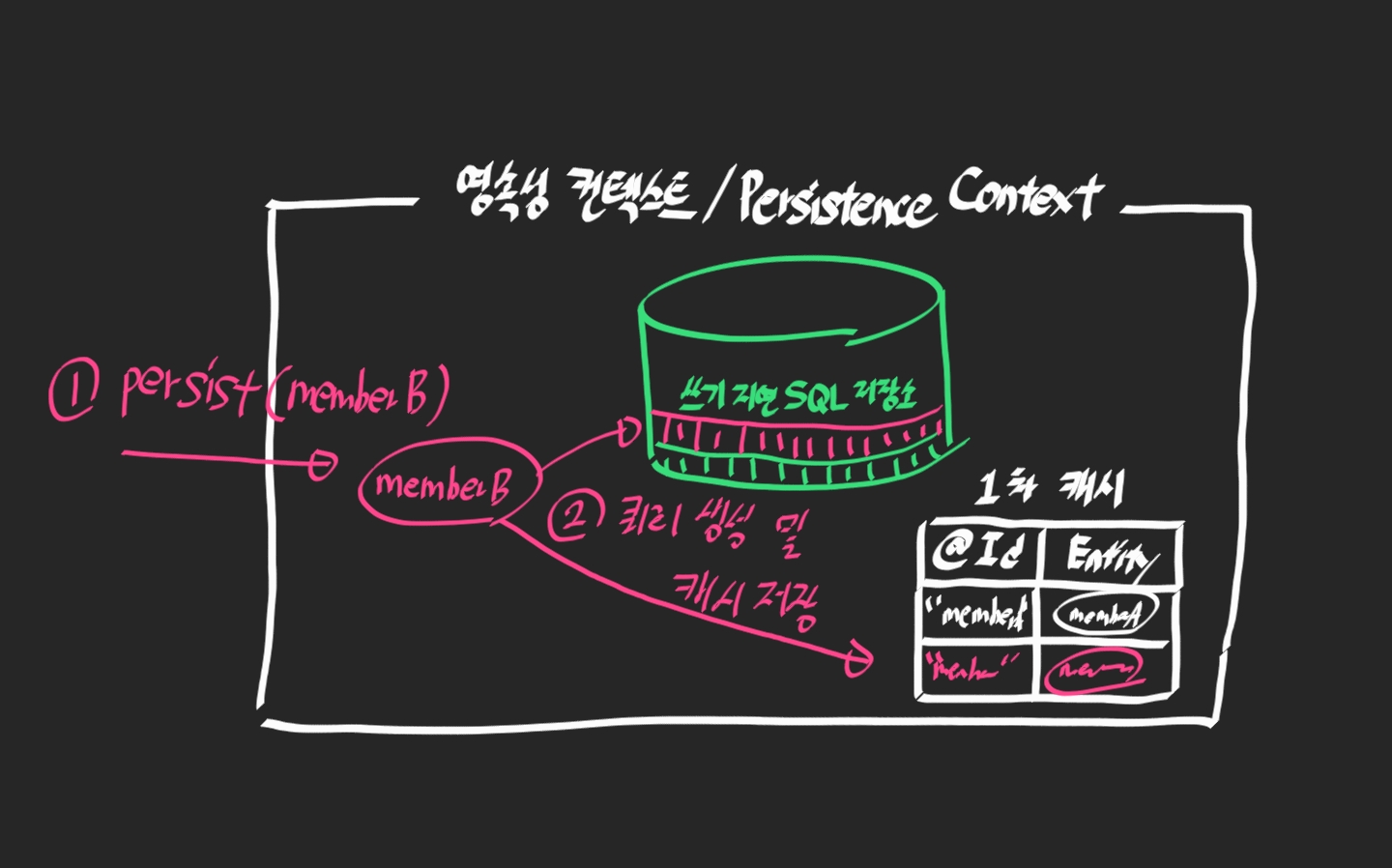
두 번째 persist()까지 동작이 마무리가 되면 이제 쿼리를 보낼 차례다.
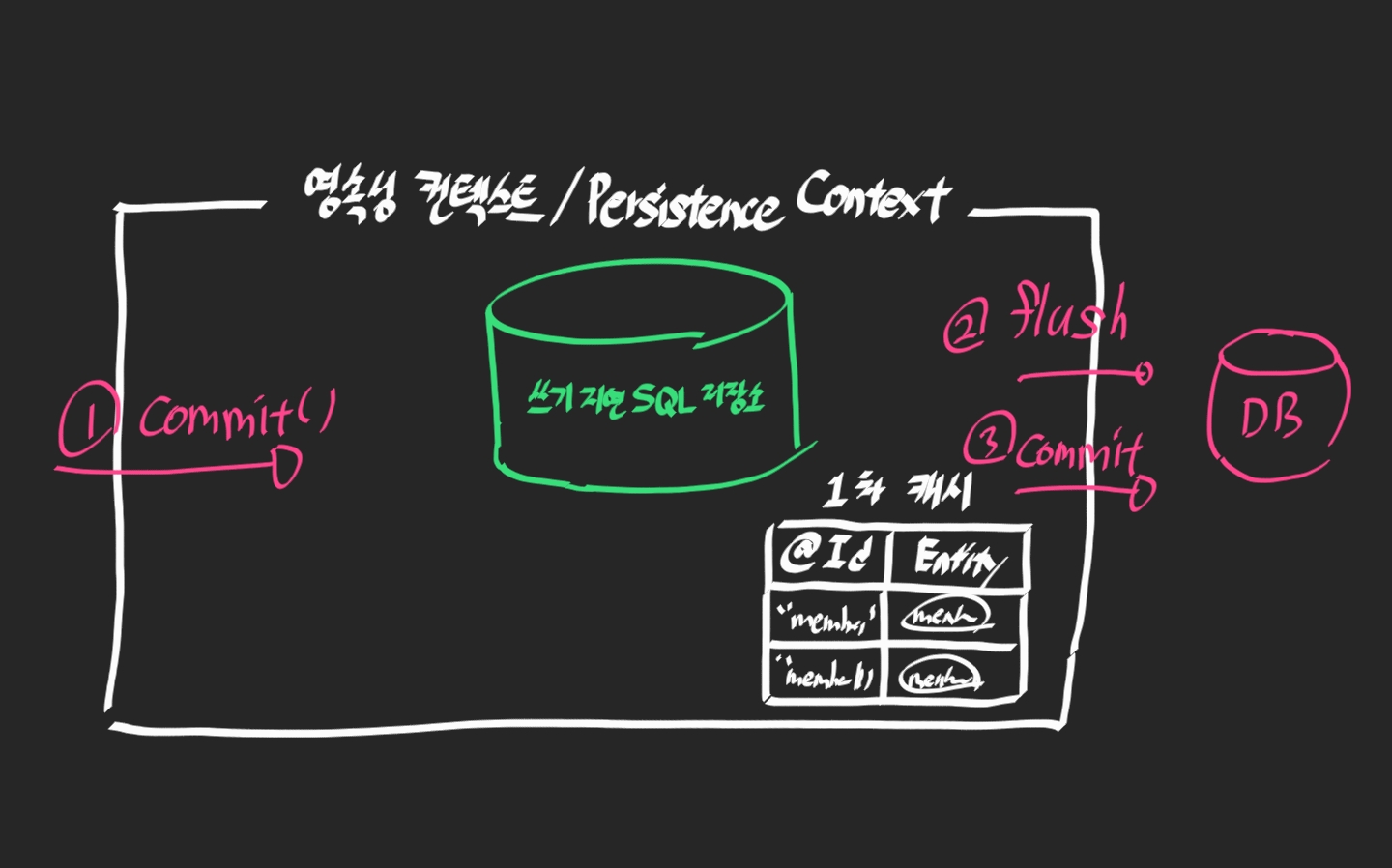
commit()이 실행되면 저장소에 있는 쿼리를 들고 DB로 flush()하면서 한번더 commit()을 한다.
Dirty Check(변경 감지)
matchingFilterEntity.setAge(editFriendDTO.getWantAge());
matchingFilterEntity.setHeight(editFriendDTO.getWantHeight());
matchingFilterEntity.setSmoking(editFriendDTO.isWantSmoke());
matchingFilterRepository.save(matchingFilterEntity);과거에 내가 작성했던 코드다. Dirty Check에 대한 개념을 모르고 본다면 별 이상 없어 보인다.
matchingFilterRepository.save(matchingFilterEntity);가 왜 필요없는지 알아본다.
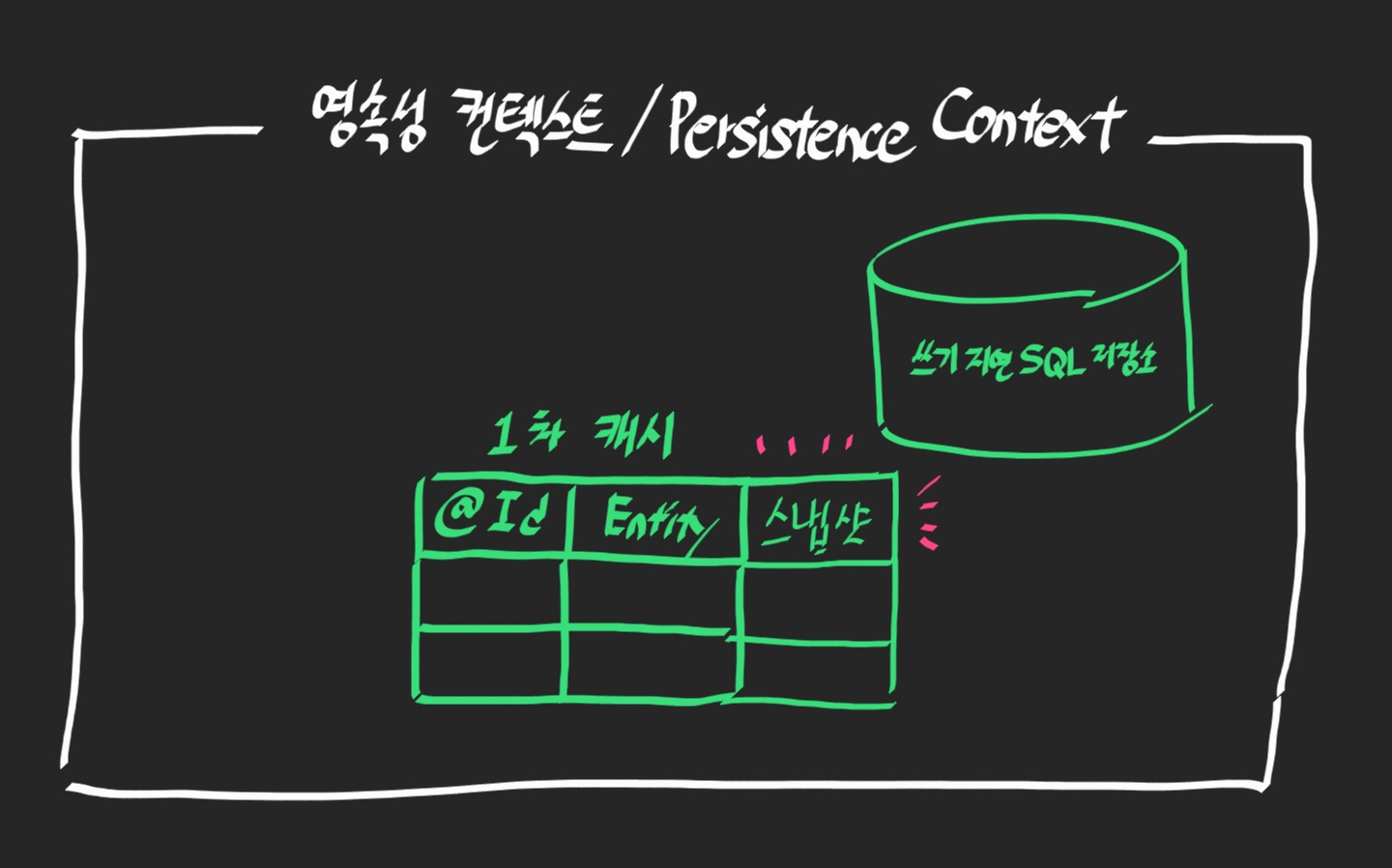
사실 1차 캐시에 숨겨진 기능인 스냅샷이 더 있다.
Persistence Context에 저장할 때, 최초 상태를 복사해서 저장해두는 것이 스냅샷이다.
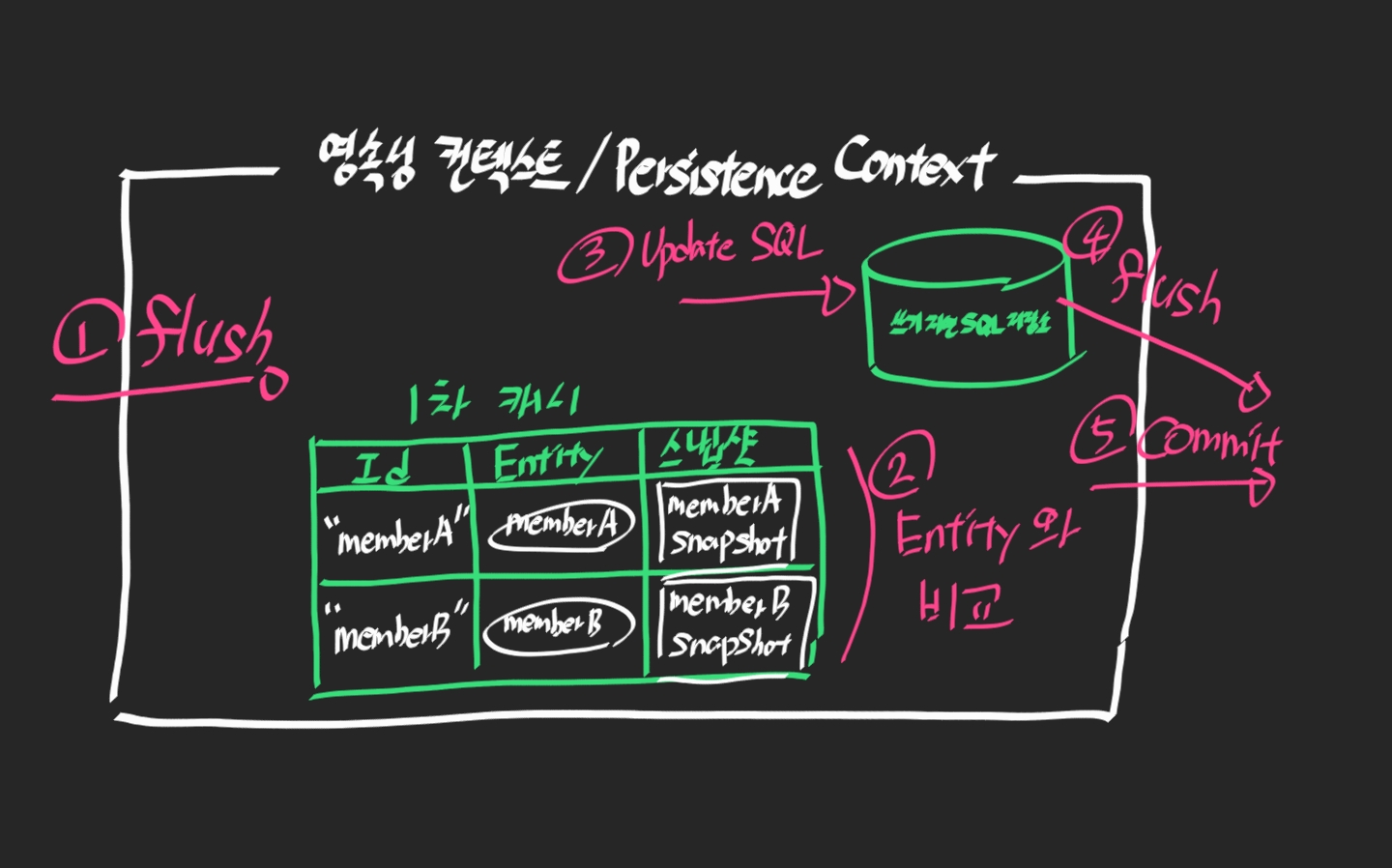
따라서 과거의 코드는 SpringDataJPA 이기때문에 flush()가 생략되어 있지만 그림과 같이 마지막 set 메서드가 동작을 마치면 해당 객체의 스냅샷과 비교를 해서 변경점을 확인하고 쿼리를 생성해준다.
참고로 JPA는 업데이트 쿼리를 생성할 때 기본 전략은 변경점이 없는 필드도 포함해서 쿼리 만든다.
따라서 해당 Entity의 필드, 컬럼이 30개 이상이 되면 @DynamicUpdate 같은 최적화 애노테이션도 고려해볼 수 있다.
준영속(detach)
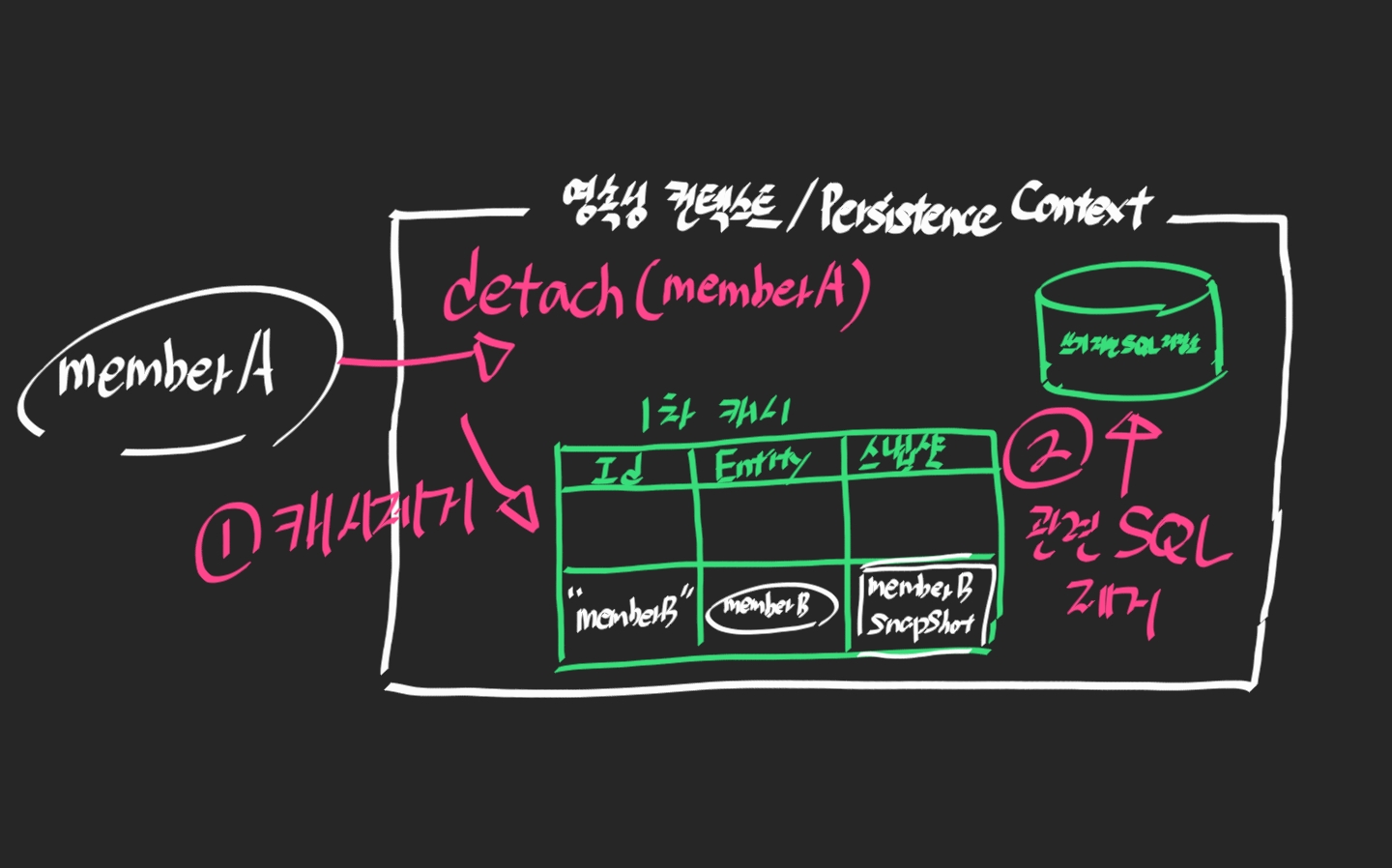
이것도 그림만 보면 아~ 더이상 관리를 안한다는 거구나?
그러면 new와 detach가 분리되어 있는 이유가 뭘까? 라고 의문이 들것이다.
해당 의문을 해결하기 전에 관련한 detach 메서드를 본다.
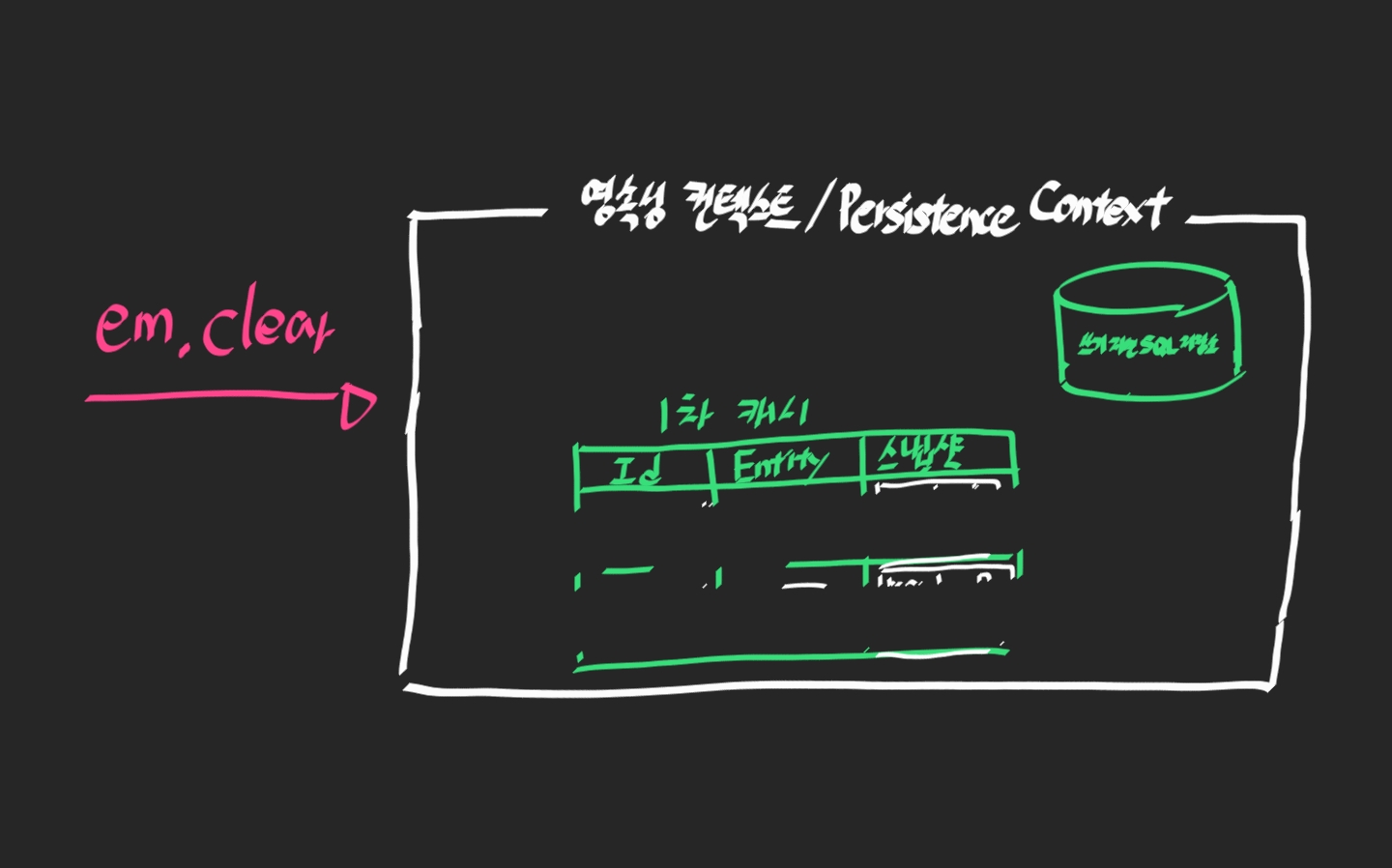
em.clear()
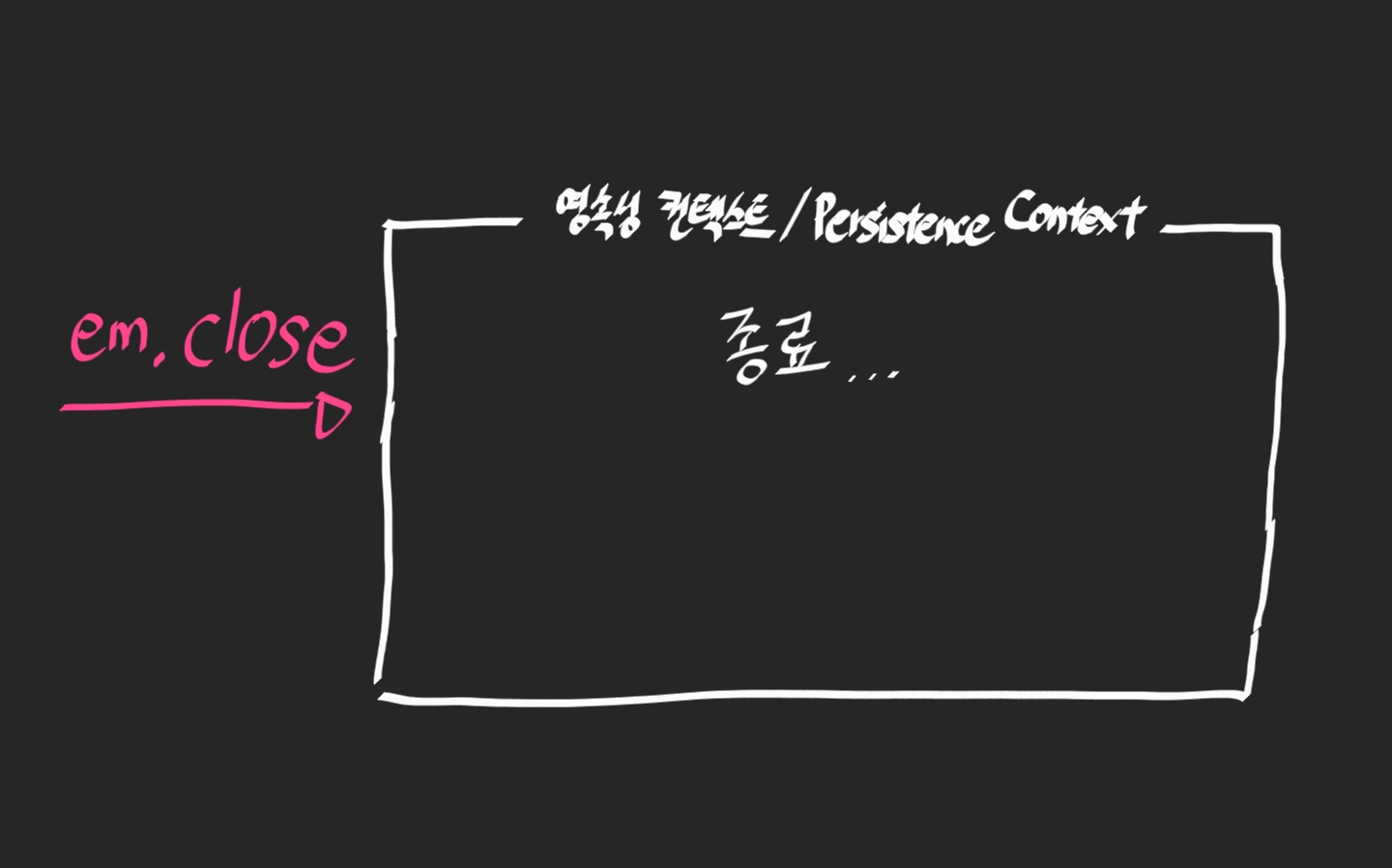
em.close()
준영속 상태 특징
거의 비영속 상태에 가깝다.
식별자 값을 가지고 있다. (이전에 영속 상태였기 때문에 Id값을 가지고 있다.)
지연 로딩을 할 수 없다.
merge()
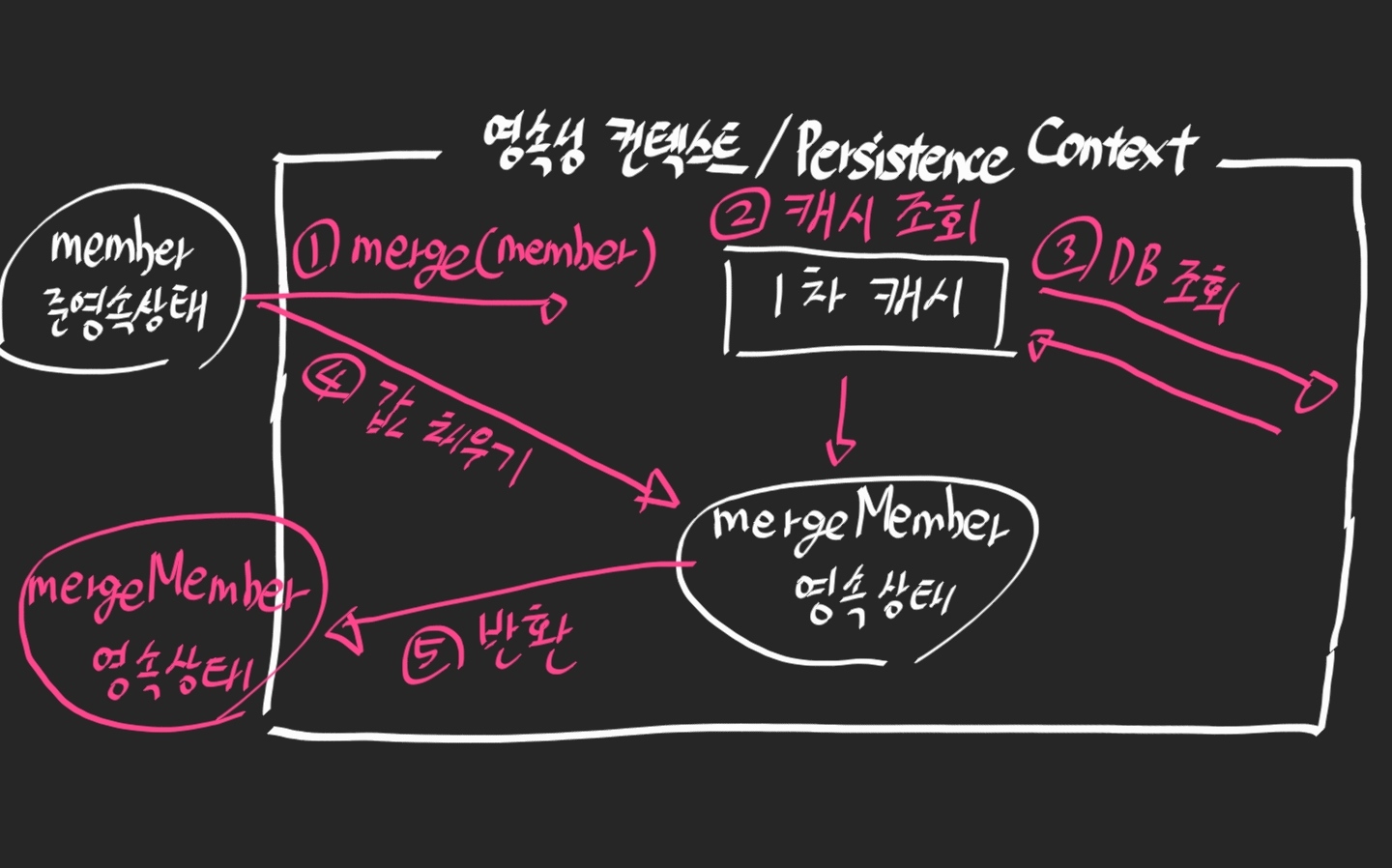
준영속 상태 특징에도 나왔듯이 비영속 상태와 준영속 상태의 가장 큰 차이점은 식별자의 유무이다.
동작 과정이 마치 find() 한 다음 update() 하는 듯한 동작이다.
준영속 상태는 식별자가 존재하기 때문에 DB에서 find() 한 다음 변경된 값을 스냅샷과 비교해서 update()하고 새로운 이름의 객체를 반환해준다.
이러한 점에서 비영속과 준영속을 구분한다.
참고로 비영속도 merge()를 통해 영속 상태로 변환할 수 있다. DB에서 조회가 안 되기 때문에 새로 생성하고 이후 과정은 같다.
정리
JPA의 Persistence Context와 Entity Manager의 내부 구조, 동작 과정, Entity 생명 주기를 알아보며 1차 캐시, 동일성 보장, 지연 쓰기, Dirty Check를 어떻게 지원하게 되는지 알 수 있게 되었다.
Persistence Context 는 모든 Entity ID에 대해 Entity 객체가 존재한다. Persistence Context 내부에는 Entity와 LifeCycle이 Managed되고 Entity Manager API는 그러한 Persistence Context 객체를 생성 및 제거를 하고, PK를 이용해 Entity를 찾고 쿼리하는데 사용된다.