추천시스템 모델을 반드시 API로 해야할까?
처음에는 꼭 모델을 API로 운영하지 않더라도, 사용자-추천 가게-추천 점수 형태의 데이터를 미리 생성해서 백엔드 DB에 저장해두면 되는 거 아닐까 싶었습니다. 백엔드팀이 이를 조회할 때 점수를 기준으로 정렬해서 상위 결과만 필터링하면 되기 때문입니다. 이렇게 하면 별도의 API 운영이나 관리가 필요 없다는 장점이 있다고 생각했습니다.
하지만 다시 생각해보니 몇 가지 단점이 있었습니다. 백엔드 팀과 데이터베이스에 대한 의존성이 커진다는 점입니다. 예를 들어, 새로운 컬럼을 추가하거나 수정하려면 백엔드 서버와 스키마에 대한 변경 요청을 해야 하고, 반영되기까지 기다려야 합니다. 이러한 이유로 저는 모델을 API로 운영하는 방식을 선택했습니다.
API를 통해서는 꼭 필요한 정보만 주고받자
그렇다면 사용자-추천 가게-추천 점수 형태의 데이터를 그대로 API를 통해 전달하는 것이 과연 적절할까요? 추천 점수 자체를 넘겨주는 것보다는, 백엔드 팀에서 실제로 필요한 정보만 선별해 전달하는 것이 더 바람직하다고 판단했습니다. 다만 이때, 어떤 실험과 어떤 모델을 통해 생성된 추천 결과인지에 대한 정보는 함께 포함하는 것이 좋습니다. 실험 정보는 추천 결과의 맥락을 이해하는 데 중요하므로, 백엔드 서버에 함께 전달될 필요가 있습니다.
{
"추천가게" : ["가게1", "가게2", "가게3"],
"실험정보" : "수미실험_001"
}
오프라인 추론과 온라인 추론
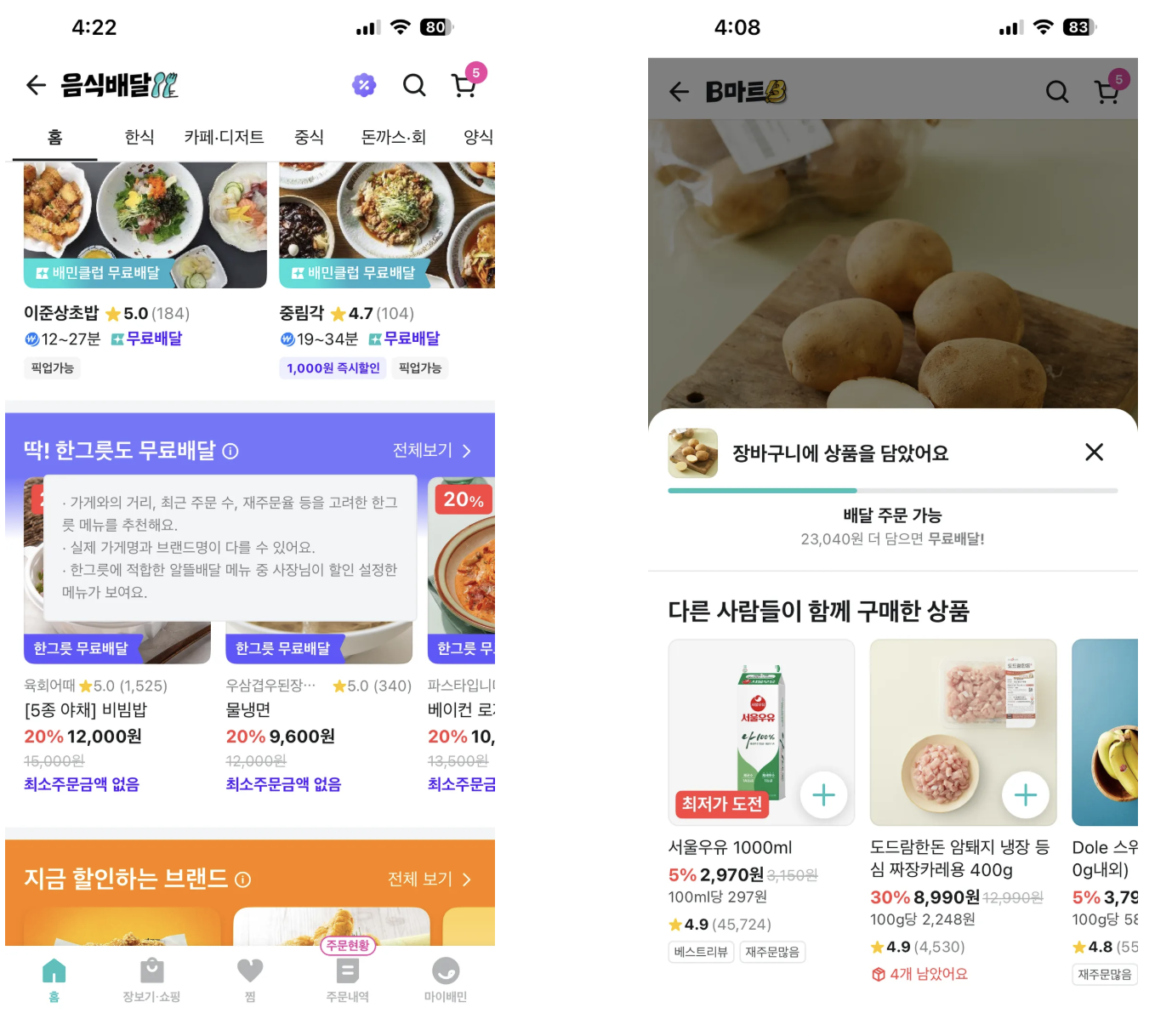
오프라인 추론은 사용자 요청이나 실시간 이벤트와 무관하게, 미리 준비된 데이터에 대해 모델을 한꺼번에 추론하고 결과를 저장해두는 방식입니다. 보통 대량의 데이터에 대해 주기적으로 수행하며, 모델 추론 결과를 사전 계산해 DB나 캐시 등에 저장해두고 서비스에서는 해당 결과를 빠르게 조회만 합니다. 왼쪽에 보이는 딱! 한그릇도 무료배달 같은 영역의 추천 결과는 매일 또는 매주 미리 계산하여 저장해두고, 사용자가 앱을 열었을 때 해당 결과만 빠르게 조회해 보여주는 구조입니다.
온라인 추론은 사용자의 요청이나 이벤트가 발생한 순간, 모델이 실시간으로 추론을 수행해 즉시 결과를 반환하는 방식입니다. 예를 들어, 사용자가 어떤 것을 클릭하거나 검색하면, 그 즉시 추천 모델을 실행해 결과를 제공하는 것입니다. 사용자 요청이 들어오면, feature store에 들어있는 피쳐를 조회하고, 미리 로드해놓은 모델에 피쳐 데이터를 입력해서 예측을 수행합니다. 오른쪽에 보이는 다른 사람들이 함께 구매한 상품 같은 영역의 추천결과는 사용자가 장바구니에 어떤 상품을 담았을 때, 그 상품과 함께 자주 구매된 상품들을 즉시 모델을 통해 추론하여 보여주는 구조입니다.
실시간 추론
‘실시간’이라는 개념은 크게 두 가지로 나눌 수 있습니다. 첫째는 모델이 동작하는 시점에 실시간으로 추론을 수행하는 방식(실시간 추론)이며, 둘째는 사용자의 클릭, 검색 등의 이벤트를 실시간으로 수집하는 방식(실시간 데이터 파이프라인)입니다.
실시간 모델 추론은 단순히 사용자 요청에만 반응하는 것이 아니라, 데이터가 연속적으로 들어오는 환경에서 지연 없이 자동으로 추론을 수행하는 방식도 포함합니다. 예를 들어, 실시간 사기 탐지 시스템은 신용카드 결제나 송금과 같은 이벤트가 실시간으로 유입되며, 각 거래가 정상인지 아닌지를 즉시 판단해야 합니다. 이처럼 데이터 스트림이 트리거가 되어 모델이 자동으로 추론을 수행하는 방식이 실시간 추론이며, 이를 구현하기 위해 실시간 데이터 파이프라인(Kafka, Spark, Flink 등)이 활용됩니다.
실시간 데이터파이프라인
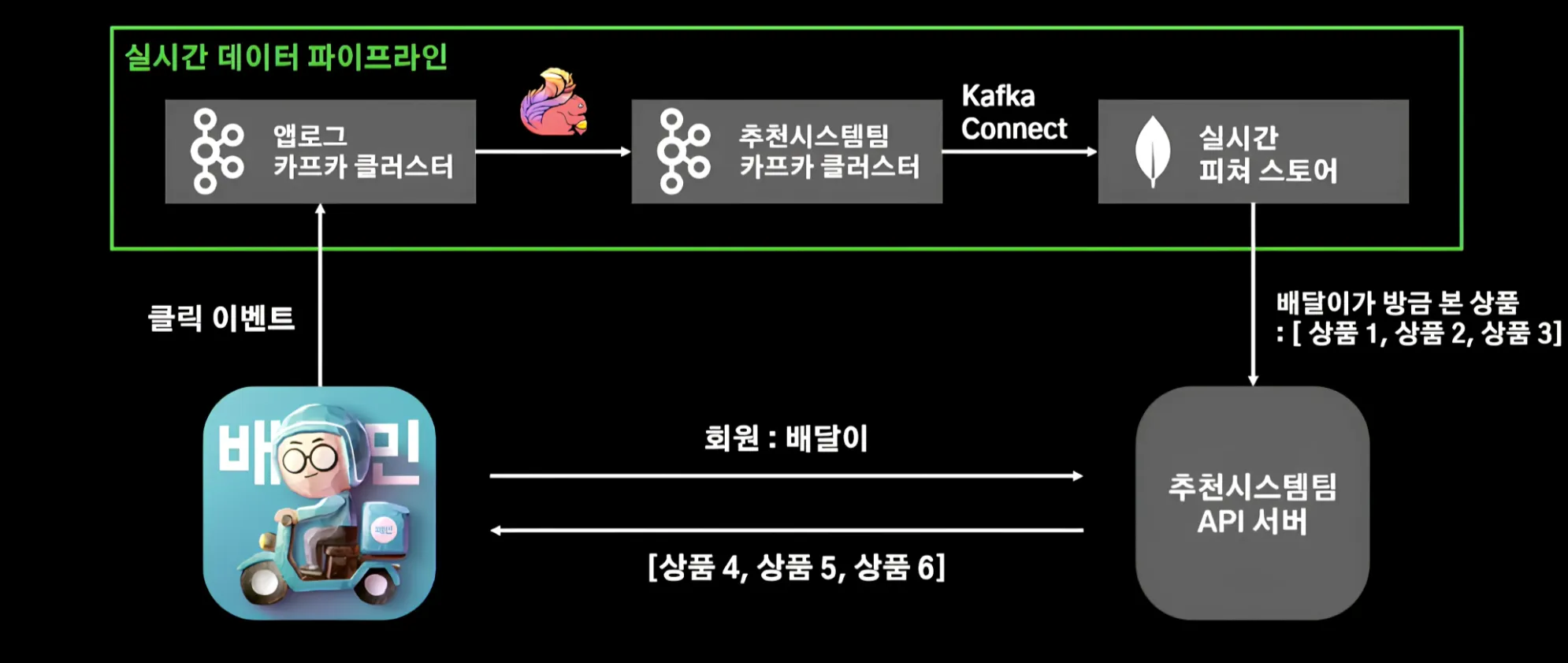
실시간 기능이 가능해지면, 예를 들어 방금 본 상품과 유사한 상품을 즉시 추천해주는 기능을 구현할 수 있습니다. 간단히 백엔드 팀에서 사용자가 본 최근 상품을 [“상품1”, “상품2”, “상품3”] 같은 리스트 형태로 ML 모델에 전달하는 방식을 생각해볼 수 있습니다.
하지만 여기에는 한계가 있습니다. 예를 들어, ‘방금’의 기준을 처음에는 최근 30분으로 두었다가, 나중에 15분으로 바꾸고 싶을 때마다 매번 백엔드 팀에 변경을 요청하고 적용되기를 기다려야 하는 번거로움이 생깁니다.
이러한 의존성 문제를 줄이기 위해, Kafka 같은 메시지 큐를 활용해 사용자 이벤트 데이터를 직접 수집하고 실시간으로 처리하는 방식을 고려할 수 있습니다. 이렇게 하면 ‘방금’의 기준 변경이나 이벤트 처리 로직을 ML팀 또는 데이터 파이프라인 쪽에서 유연하게 관리할 수 있는 장점이 있습니다.
추론 방식의 선택
현재는 온라인 추론이 반드시 필요한 ML 기능이 없다고 판단하여, 먼저 오프라인 추론 기반의 추천 시스템을 구축하기로 결정했습니다. 이후 추천 시스템 기능을 고도화할 시점에 온라인 추론 방식으로 확장할 계획으로 방향을 잡았습니다. 실시간 처리 역시 현재 단계에서는 필요성이 낮다고 판단되어, 향후 단계에서 도입하는 것으로 방향을 잡았습니다.